redis-底层数据结构
redis关键结构
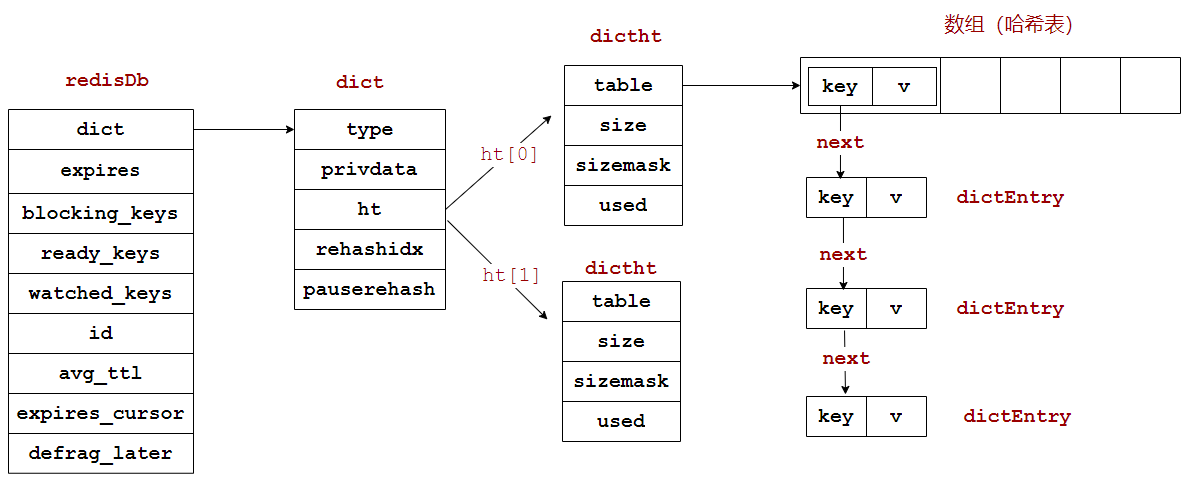
一般情况下,dictEntry的value,是redisObject
数据类型与底层数据结构的关系
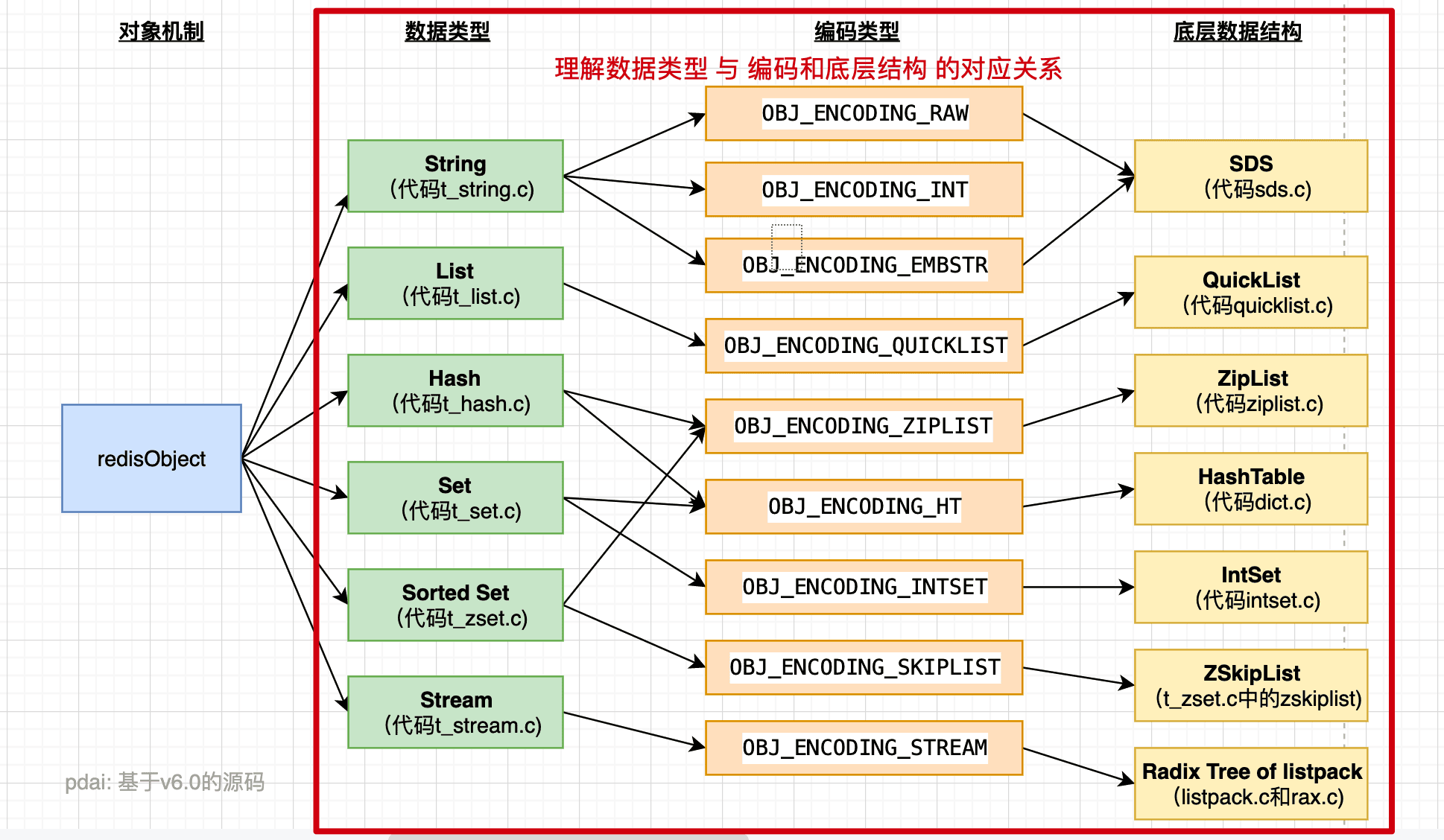
String
sds
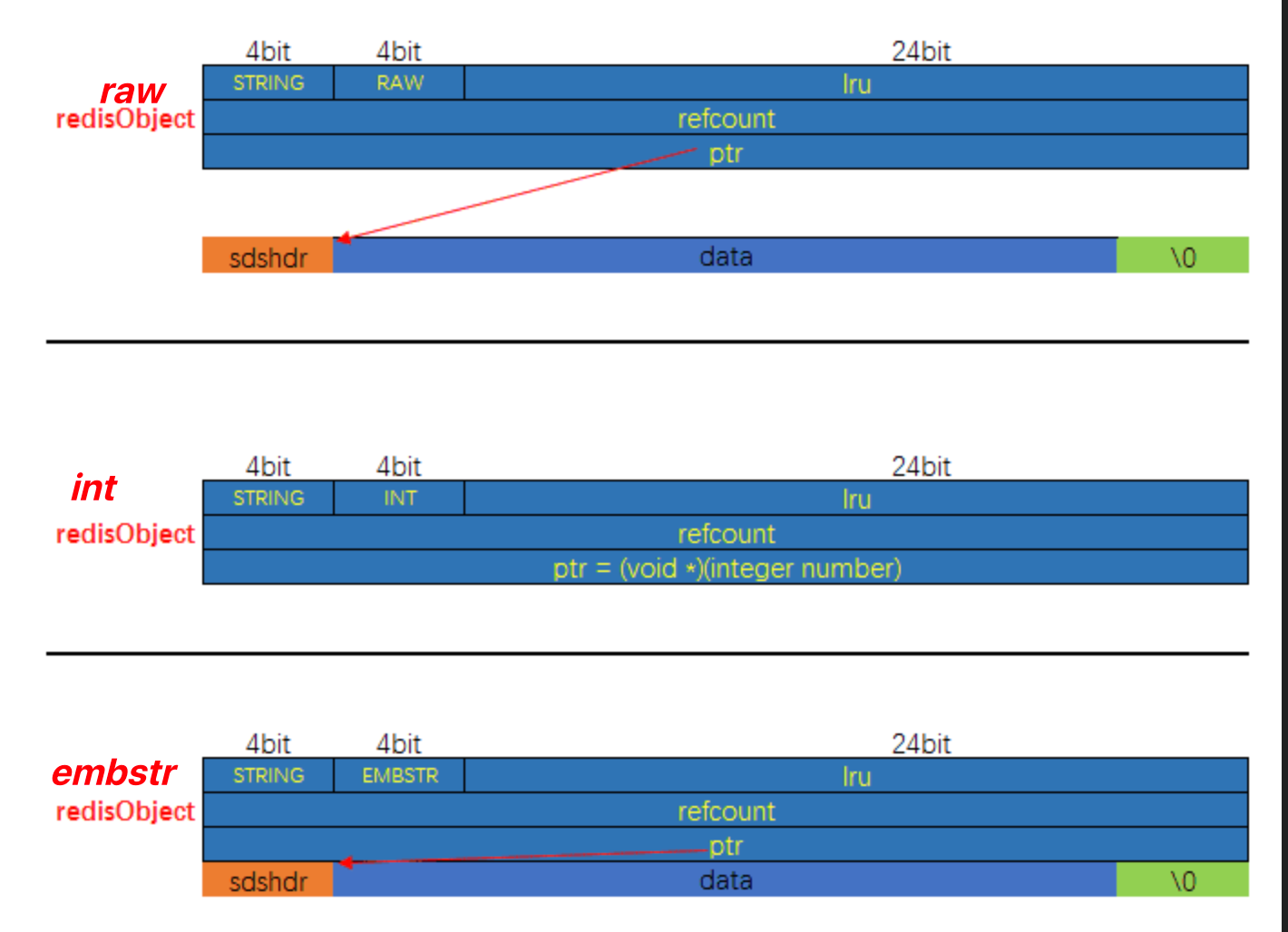
字符串对象的编码可以是int,raw或者embstr。
int 编码:保存的是可以用 long 类型表示的整数值。embstr 编码:保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。raw 编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
编码转换条件
当 int 编码保存的值不再是整数,或大小超过了long的范围时,自动转化为raw。
对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节
List
ziplist —> quicklist —> listpack
Hash
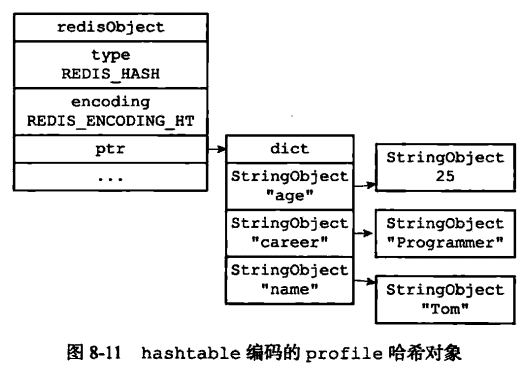
哈希对象的编码可以是 ziplist 或者 hashtable;对应的底层实现有两种, 一种是ziplist, 一种是dict。当采用HT编码, 即使用dict作为哈希对象的底层数据结构时, 键与值均是以sds的形式存储的.
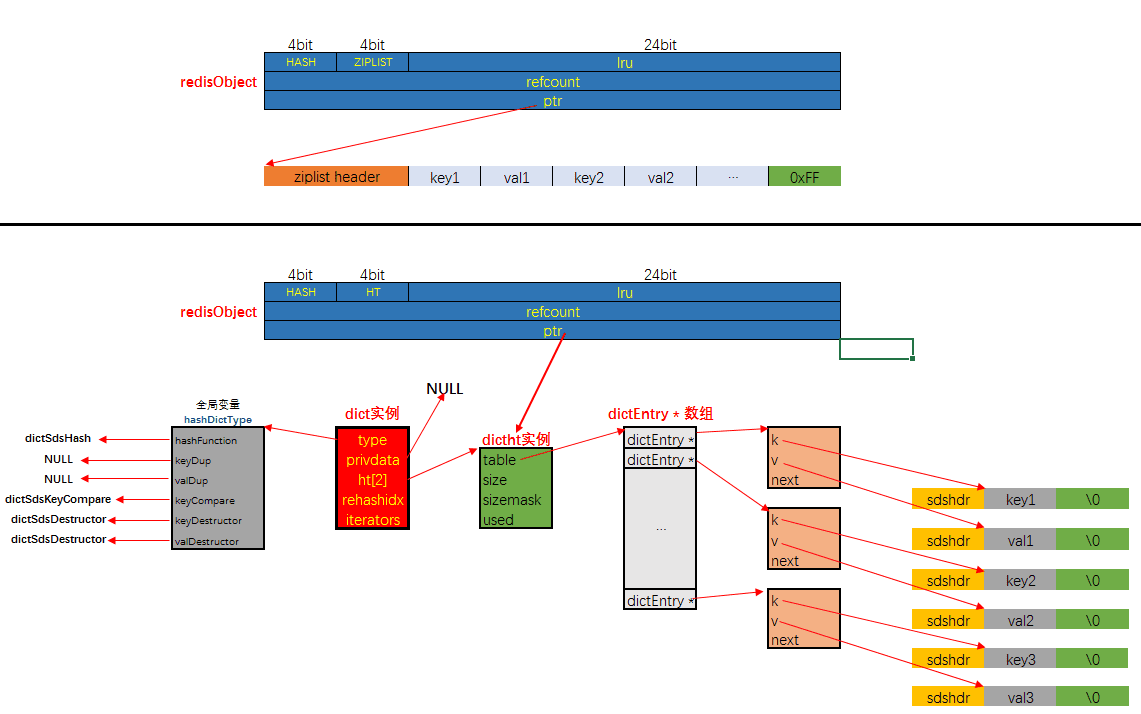
hset profile name "Tom"
hset profile age 25
hset profile career "Programmer"使用ziplist的存储

使用hashtable的存储
转换条件
1、列表保存元素个数小于512个
2、每个元素长度小于64字节
不能满足这两个条件的时候使用 hashtable 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
利用zipList来替代大量的Key-Value.
Set
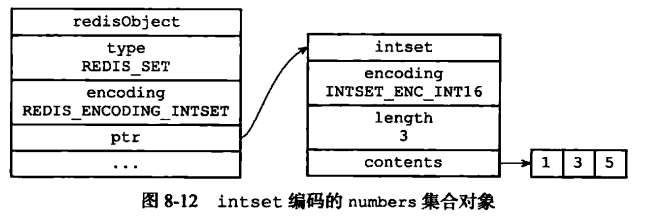
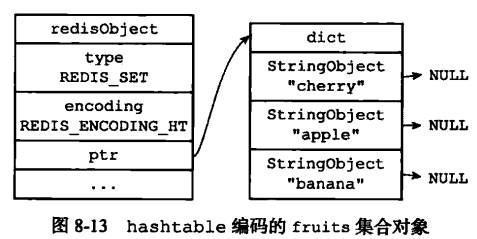
intset和hashtable
集合对象的编码可以是 intset 或者 hashtable; 底层实现有两种, 分别是intset和dict。 显然当使用intset作为底层实现的数据结构时, 集合中存储的只能是数值数据, 且必须是整数; 而当使用dict作为集合对象的底层实现时, 是将数据全部存储于dict的键中, 值字段闲置不用.
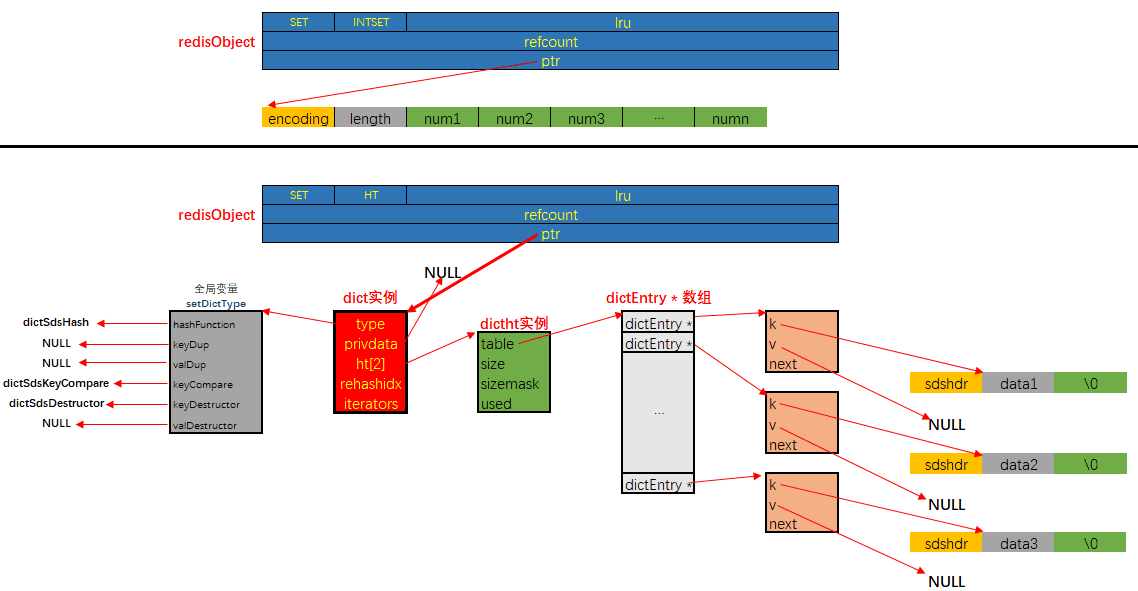
SADD numbers 1 3 5
SADD Dfruits "apple" "banana" "cherry"
编码转换条件
当集合同时满足以下两个条件时,使用 intset 编码:
1、集合对象中所有元素都是整数
2、集合对象所有元素数量不超过512
不能满足这两个条件的就使用 hashtable 编码
Zset
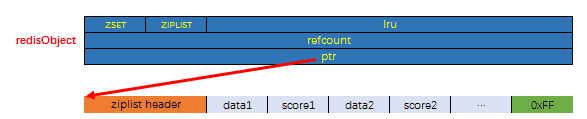
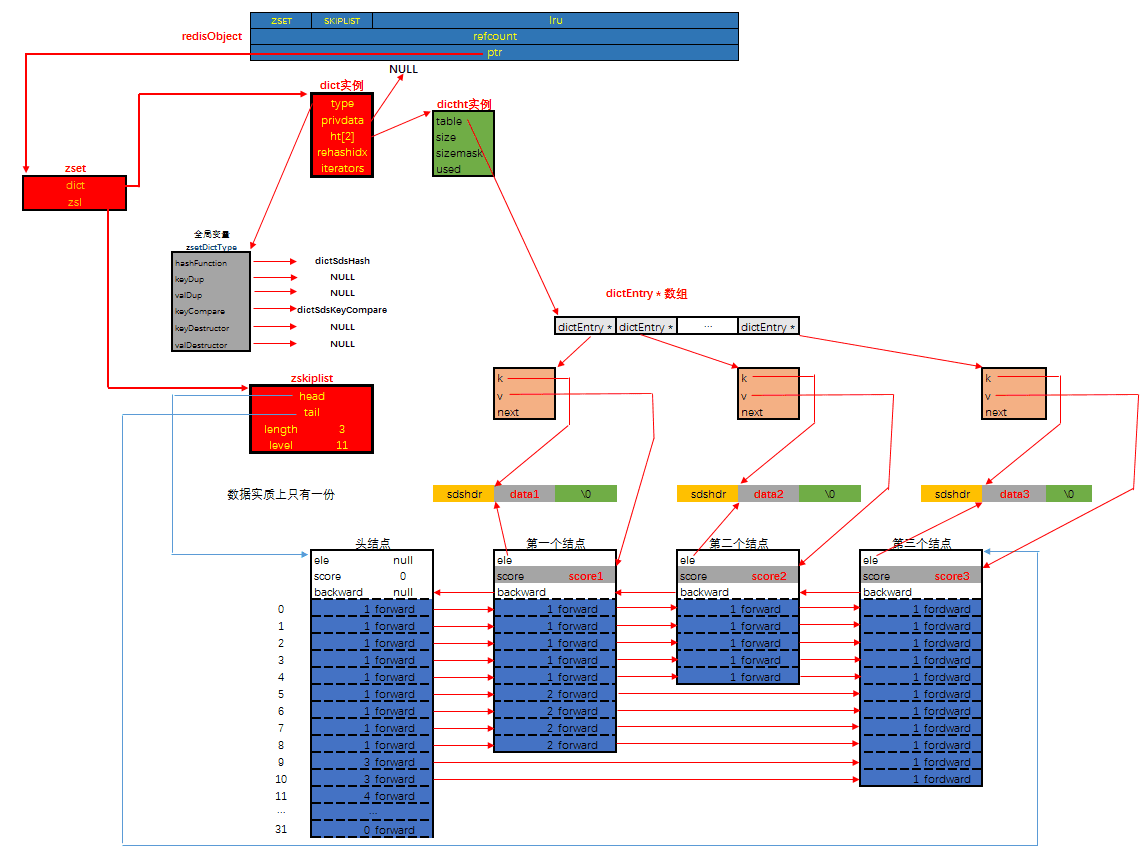
实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合
编码转换
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
1、保存的元素数量小于128;
2、保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码。以上两个条件也可以通过Redis配置文件zset-max-ziplist-entries 选项和 zset-max-ziplist-value 进行修改。
Stream
为了节省内存空间,在 Stream 数据类型的底层数据结构中,采用了 radixTree 和 listpack 两种数据结构来保存消息.