sds
技巧💡
简单动态字符串,
基本结构
先来看下基本的结构, 类似java中的String,需要有个长度标识len,当前字符串的大小,而不是以\0结尾来标识,但是为了兼容C,buf内容的最后,会默认加上\0.
alloc,是总共分配内存大小。进行预分配,有效使用内存。
flags: 主要用来表示类型
buf: 真正内容。
- 二进制安全: SDS可以保存二进制数据,而不是以NULL结尾的字符串。这使得 Redis 可以存储非字符串的数据类型,例如二进制数据和经序列化的对象等
- 预分配内存、惰性空间释放。减少了频繁的分配内存与释放。
注意点:
紧凑型:
为了尽可能的较少存储空间,根据不同的字符串长度,分配不同的类型。
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 { // 对应的字符串长度小于 1<<5.
unsigned char flags; // 左3bit 是类型, 后5bit是长度。 所以存储长度 1<<5
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8
uint8_t len; /* 已使用长度,1 字节存储 */
uint8_t alloc; /* 总长度 */
unsigned char flags;
char buf[]; // 真正存储字符串的数据空间
};
struct __attribute__ ((__packed__)) sdshdr16 { // 对应的字符串长度小于 1<<16
uint16_t len; /* 已使用长度,2 字节存储 */
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 对应的字符串长度小于 1<<32
uint32_t len; /* 已使用长度,4 字节存储 */
uint32_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 { // 对应的字符串长度小于 1<<64
uint64_t len; /* 已使用长度,8 字节存储 */
uint64_t alloc;
unsigned char flags;
char buf[];
};
encoding中raw和embstr的区别
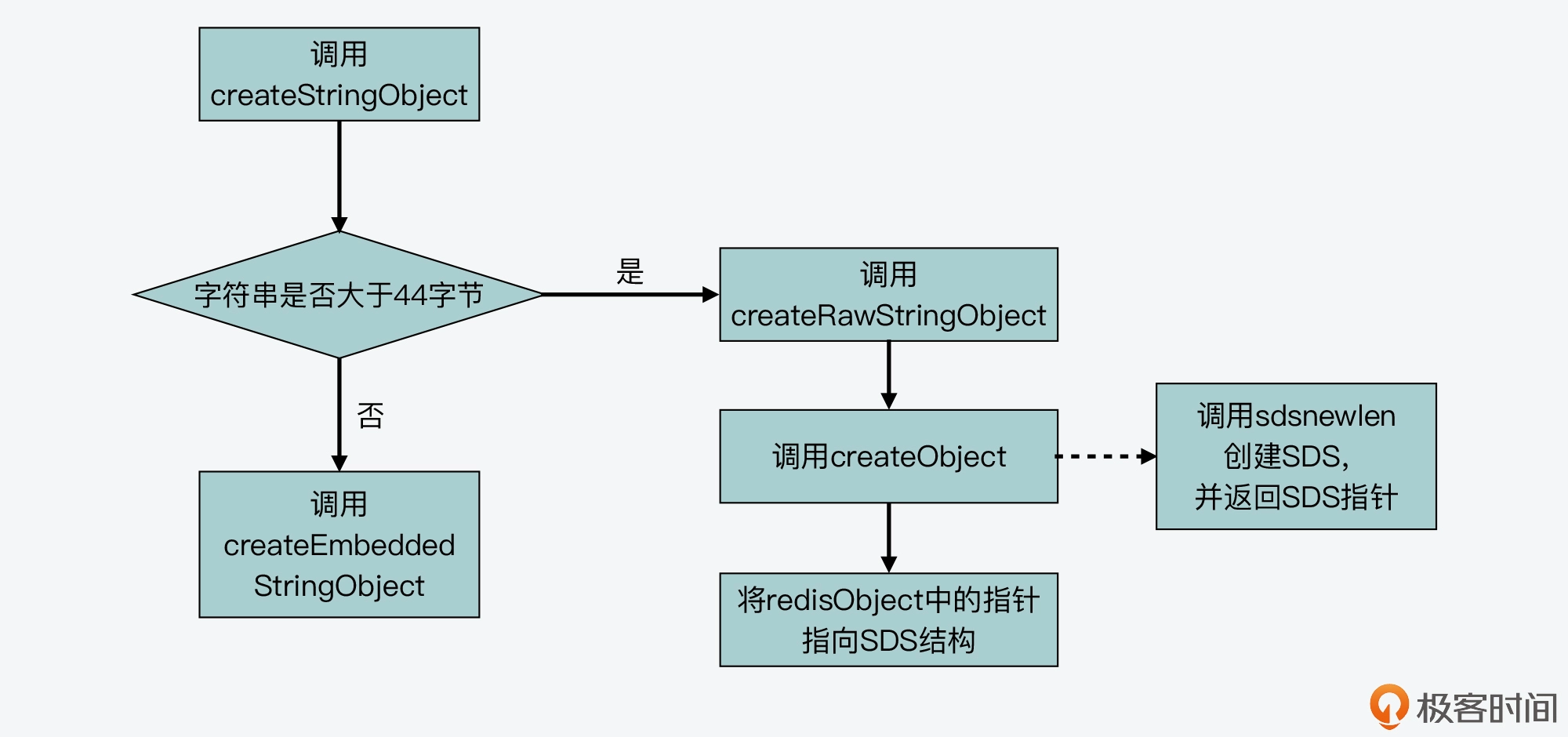
embstr: 在分配内存的时候,是直接和sds分配的,而不是额外分配。 避免内存碎片和两次内存分配的开销了。
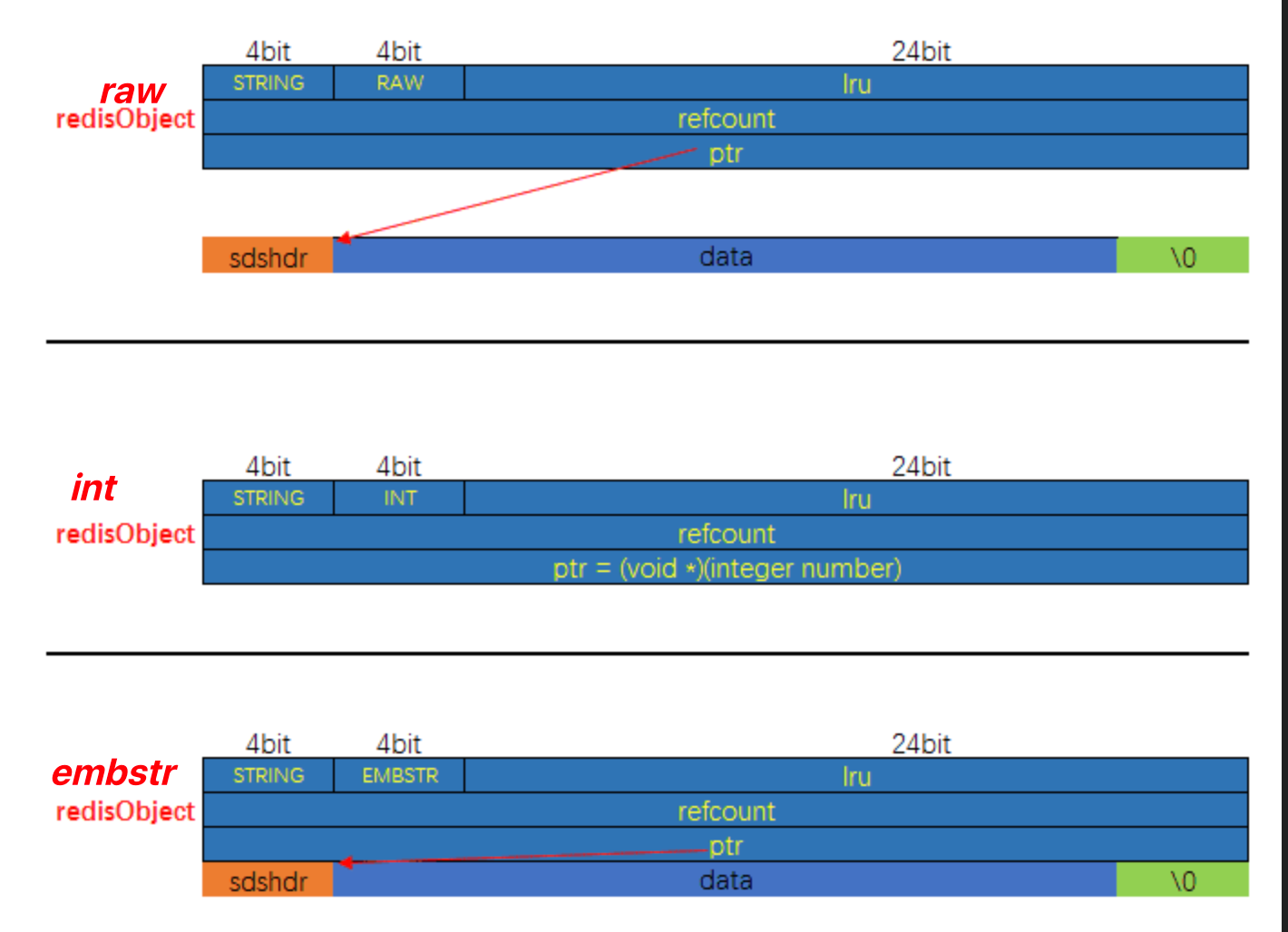
- 如果长度<=44字节,则分配的内存与sds是连续的。
- 如果长度>44自己,则额外指针指向buf
// redis源码object.c
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
// 小于44字节,使用embstr
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}embstr
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 注意这里,redisobject 和sds是一起分配内存的。而且使用的是sdshr8
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
// 类型为String
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}raw
// 创建raw字符串
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}为什么是 44 字节?
在 Redis 中,如果 SDS 的存储值大于 64 字节时,Redis 的内存分配器会认为此对象为大字符串,并使用 raw 类型来存储,当数据小于 64 字节时(字符串类型),会使用 embstr 类型存储。既然内存分配器的判断标准是 64 字节,那为什么 embstr 类型和 raw 类型的存储判断值是 44 字节?
为什么内存分配器分配标准是64字节?💡
- 可能与cache-line有关
这是因为 Redis 在存储对象时,会创建此对象的关联信息,redisObject 对象头和 SDS 自身属性信息,这些信息都会占用一定的存储空间,因此长度判断标准就从 64 字节变成了 44 字节。
已知redisObject中占用了16字节。那么SDS能够占用的字节就是 64-18 = 48字节
我们知道,sds的数据结构有很多种。那使用哪种呢?sdshdr5、sdshdr8还是sdshdr16?为了尽可能存储更多数据,sdshdr8能存储的数据长度为 1<<8。 是最合适的。所以选择sdshr8
还有个要注意的是,我们知道sds的buf默认都会默认添加\0,会占用1个字节。所以buf能存储的最大空间为 48 - len(1) - alloc(1) - flags(1) - buf\0(1) = 44
struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8
uint8_t len; /* 已使用长度,1 字节存储 */
uint8_t alloc; /* 总长度 1字节*/
unsigned char flags; /*1字节*/
char buf[]; // 真正存储字符串的数据空间
};