ziplist
ziplist的过渡💡
在redis中,有很多地方都用到了ziplist。
在设计使用什么数据结构的时候,首先要做的是明确需求,即会怎么进行操作。
在redis的list数据类型中,会使用 lpush,rpush等命令,即需要头尾进行插入。
所以至少需要支持
- 正向遍历
- 逆向遍历
- 快速定位头部和尾部。
方案1,双向链表
{
*data
*pre; -- 8字节
*next -- 8字节
}struct node
优点:
支持正逆向遍历,O(1)定位头尾部
缺点:
- 不管data的内容多大,都需要至少16字节的pre和next指针。浪费内存
- 无法精细化处理存储空间
ziplist(可变长数组)
ziplist就是为了解决双向链表对浪费内存的情况。
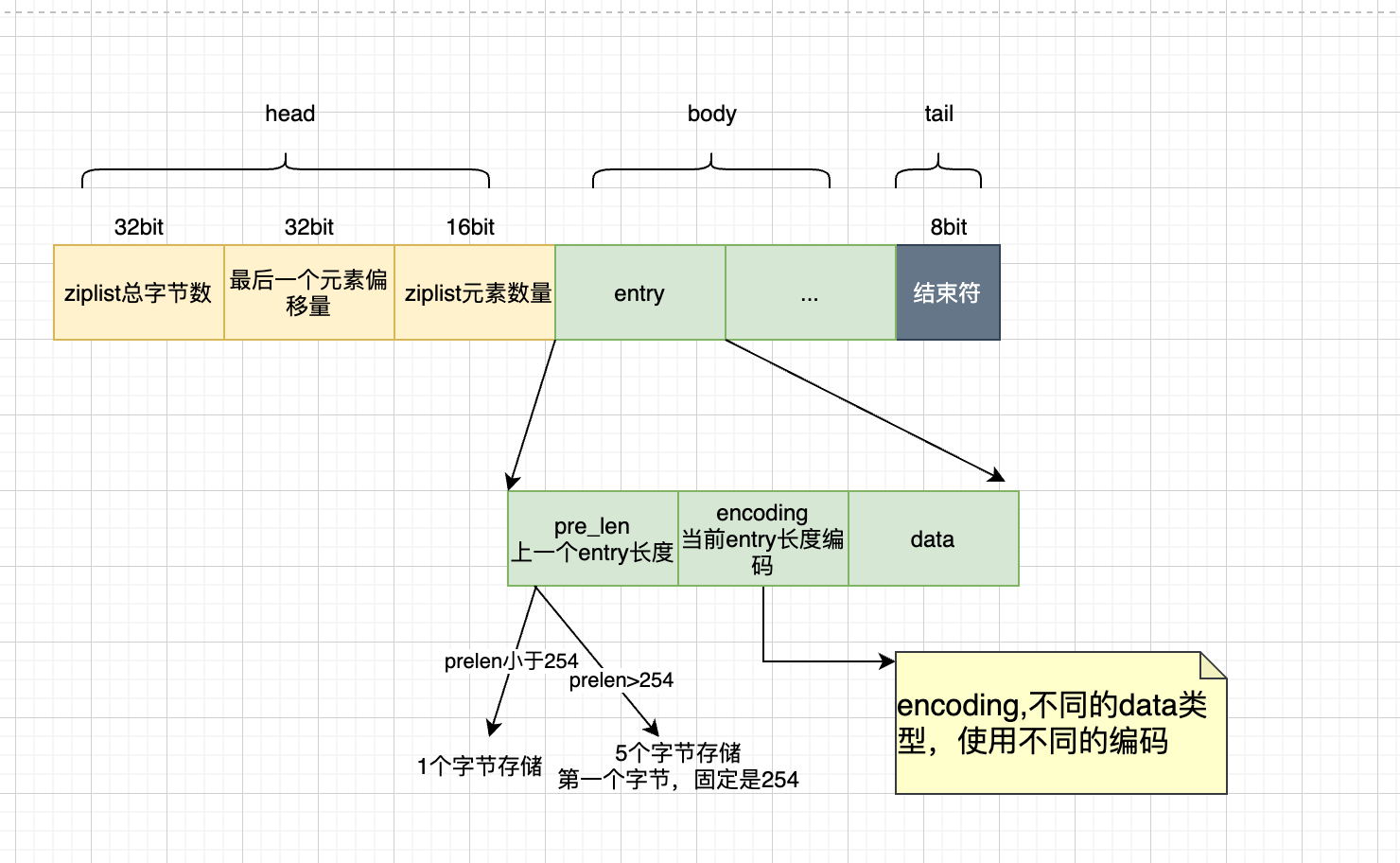
分成3部分, head data tail
-
head,作为元数据。
- 总字节数
- 最后一个元素偏移量,为了快速定位最后一个节点数据
- ziplist元素数量,快速获取entry总量
-
entry, 存储数据数组。
- pre_len, 存储上一个entry的长度。是为了逆向遍历时,key找到上一个entry
- pren_lensize,是指存储pre_len所占用的字节。
- 比如,上一个entry长度只有254时,没必要申请太大的内存空间,来存储长度
- pre_len<254, 占用1个字节
- pre_len>=254, 占用5个字节,其中第一个字节固定值是254
- pren_lensize,是指存储pre_len所占用的字节。
- encoding,当前entry长度编码。主要是为了适配不同的data类型,使用不同的编码。
- data: 真实数据
优点:
- pre_len, 存储上一个entry的长度。是为了逆向遍历时,key找到上一个entry
-
占用紧凑,尽可能的精细化控制内存占用。根据上一个entry长度和当前entry长度,使用不同的空间在存储。
-
支持正向遍历过程
- head是固定字节数,跳过head的大小,定位到第一个entry
- 计算出entry的占用的字节数
- 根据pren_len的值,计算出pren_lensize占用大小
- 根据encoding,计算出encoding和data的占用大小。
- 跳过entry的占用字节数,跳转到nextEntry
-
逆向遍历过程
- 根据head种的最后一个元素偏移量,定位到最后一个entry
- 获取entry中的pren_len
- 跳过pren_len,即可找到前一个entry
缺点:
- 遍历过程,时间复杂度是O(N),所以如果元素数量太多,会导致性能太慢。
- 由于entry中的pre_len,存储的是上一个entry的长度,并且可能占用的内存是1个字节或者5个字节。如果中间某个entry的内容发送变化,导致后续的entry长度发生了变化,会导致 级联更新
quicklist(链表 + ziplist)
因为ziplist中的entry,存储的是上一个entry的长度,导致了级联更新问题。
quicklist 的设计,其实是结合了链表和 ziplist 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 ziplist
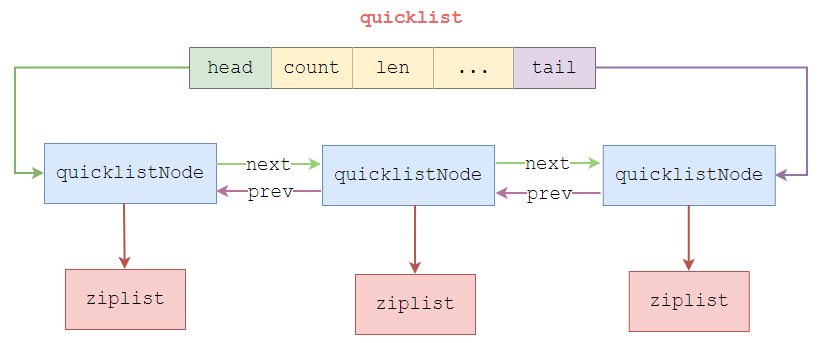
在插入数据时,出现以下条件,则进行创建新的quicklistNode
- 单个 ziplist 是否不超过 8KB,
- 单个 ziplist 里的元素个数是否满足要求
这样一来,quicklist 通过控制每个 quicklistNode 中,ziplist 的大小或是元素个数,就有效减少了在 ziplist 中新增或修改元素后,发生连锁更新的情况,从而提供了更好的访问性能.
listpack(ziplist的变种,存储当前entry长度)
与ziplist的优化思路💡
- ziplist的主要问题,在于存储了pre_len,导致了级联更新。pren_len的主要作用,在于逆向遍历,那有什么办法,不存储pre_len,又能进行逆向遍历呢?
listpack,通过计算出当前entry的长度,就可以定位到上一个entry结束指针。那如何知道,entry的长度呢?主要在于,对entry_len的特殊处理。将每个字节的最高位bit,用来判断entry-len是否结束。
最高位0,代表entry_len还没结束。
最高位1,代表entry_len结束。
逆向遍历时,依次获取最后的字节,判断最高位。知道最高位是1,代表了entry_len的长度。即可算出当前entry_len的长度。从而定位到当前entry

- head 元数据
- 总字节数
- 元素数量
- entry列表,只存储当前entry的长度
- encoding-type: 保存了数据类型及数据长度
- data: 实际数据
- entry-len:(element-tot-len) 每个字节的最高位,是用来表示当前字节是否为 entry-len 的最后一个字节(低 7 位采用了大端模式存储)
- 最高位为 1,表示 entry-len 还没有结束,当前字节的左边字节仍然表示 entry-len 的内容;
- 最高位为 0,表示当前字节已经是 entry-len 最后一个字节了。
- tail: 固定值结束符:255
优点:
- 紧凑存储,解决了ziplist的级联更新问题。通过encoding_type,尽可能控制内存占用
- 支持正向遍历
- 首先,listpack 保存了 LP_HDR_SIZE,通过该参数可以直接将指针移动到第一个 entry 列表项
- 先计算 encoding + data 的总长度 len1
- 通过 len1 可计算出 element-tot-len 的长度
- len1 + element-tot-len 之和即为 entry 总长度 total-len
- 向后移动 total-len 即为下一个列表项的起始位置
- 支持逆向遍历()
- element-tot-len的特殊编码方式:element-tot-len 每个字节的最高位,是用来表示当前字节是否为 element-tot-len 的最后一个字节
- 从当前列表项起始位置的指针开始,向左逐个字节解析(碰到最高位为1,即结束),得到前一项的 element-tot-len 值,也就可以得到encoding + data的总长度,从而得出entry的总长度;
- 减去entry的总长度,就得到了前一个entry的地址
反向查询
为了支持反向查询,特意设计了参数element-tot-len,怎么说呢?因为对于正向查询,encoding保存了数据类型及数据长度,就可以知道整个entry的长度
element-tot-len的特殊编码方式:element-tot-len 每个字节的最高位,是用来表示当前字节是否为 element-tot-len 的最后一个字节,这里存在两种情况,分别是:
- 最高位为 1,表示 element-tot-len 还没有结束,当前字节的左边字节仍然表示 element-tot-len 的内容;
- 最高位为 0,表示当前字节已经是 element-tot-len 最后一个字节了。而 element-tot-len 每个字节的低 7 位,则记录了实际的长度信息。
这里需要注意的是,element-tot-len 每个字节的低 7 位采用了大端模式存储,也就是说,entry-len 的低位字节保存在内存高地址上。
正是因为有了 element-tot-len 的特别编码方式,lpDecodeBacklen 函数就可以从当前列表项起始位置的指针开始,向左逐个字节解析,得到前一项的 element-tot-len 值,也就可以得到encoding + data的总长度,从而得出entry的总长度;减去entry的总长度,就得到了前一个entry的地址~
作者:柏油
链接:7093530299866284045
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3. 在新版的reids中,已经大量替换了ziplist。
缺点:
- 同ziplist,存储元素更大时,进行遍历时会导致性能差。
技巧💡
ziplist, listpack遍历性能差的问题,只在元素较少时才使用。当元素数量太大时,底层的数据结构就会变化。
如zset,在元素数量较少时,使用ziplist,较多时,使用 跳跃表