- 引言
- 为什么需要数据库?
- DBMS的提出
- 关系模型
- 主键,表示一个tuple的唯一标识。 可自增或数据库自动生成,如mysql
- 外键
- 高级语言
- 数据库架构
- [存储引擎]
- 传统的 DBMS 架构都属于 disk-oriented architecture,即基于磁盘的
- 存储引擎,主要存储 索引、数据、元数据等
- 磁盘管理
- 为什么要有DBMS的磁盘管理。
- 基于计算机存储,同时获得易失性存储器的性能和非易失性存储器的容量,让 DBMS 的数据看起来像在内存中一样
- 为什么不用OS的磁盘管理?数据系统可以做出更好的选择,比如合适的时机刷脏页、预读取等策略
- 磁盘管理的核心问题
- 使用磁盘文件来表示数据库的数据。(元数据、索引、数据表等)
- 如何管理数据在内存与磁盘之间的移动.数据库bufferpool
- 数据库在磁盘的展示
- 文件层级
- 对于操作系统来说,就是一个普通的二进制文件。需要使用数据库系统来分析这个二进制文件。一般来说,索引、元数据等数据,会放在不同的文件上。
- 有些数据库,会使用定制的文件系统。但是带来的提升并不大(10%),所以大部分的数据库都没有使用特定的文件系统。
- 数据库page层级
- 为什么需要页?局部性原理,进行预读取。
- 页作为磁盘和内存的之间的基本交互单位。
- 不同的页概念
- 硬件页 4KB
- OS page 4KB
- DBMS (1-16KB) 4kB: sqllite, oracle 8KB: sqlserver/postgresql 16kB: mysql 。如果保证数据完整性, DoubleWrite
- 页的管理(哪些是空闲页)
- 如果页只存在单文件,可以根据固定大小 * offset来定位
- 但是,一般我们都是多文件。如果管理
- 链表
- 记录 free page list 和data page list
- 优化,双向链表
- page directory,页目录,定义一段数组,每个数组进行页的地址。
- 页的布局 page layout = header + data
- header
- pageSize 页大小
- checksum 校验,判断页的完整性
- 数据库版本
- 事务可见性
- 压缩信息
- data这里的数据,可以是数据,日志,索引等信息。
-
Tuple-oriented(存数据)
- strawman idea(基本不用), 固定大小一值append,容易碎片化
- slotted pages(大部分DBMS都使用这个)
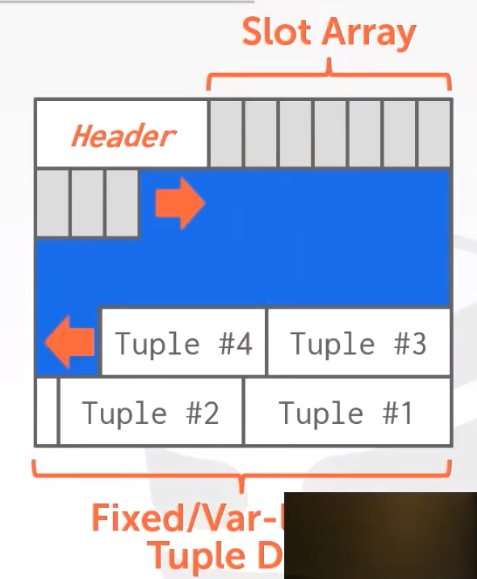
-
- 只存储记录日志,不存具体数据。增删改,快,因为是顺序写。
- 查慢,因为要计算出来。
- 优化方案
- 压缩日志,如2个update语句更新同一个字段,取最后一条。
- 分级压缩

-
- header
- tuple层级
- tuple layout = header + attributes
- header
- 可见性信息,并发控制用
- bitMap for null value值。标记哪些值是null value
- attributes
- header
- tuple storage:如何使用tuple来表示数据?(字节序列)
- 溢出页,tuple 太大时,直接使用指针来指向真正的存储的数据。真实数据存在溢出页中。专门放比较大的数据
- 元数据存哪?把元数据当系统表来处理
- tuple layout = header + attributes
- 存储模式
- 文件层级
- 索引文件的存储结构,这里与数据的存储有关。
- Tuple-oriented存数据,使用In-place update structure就地更新结构,如B+树。是直接覆盖旧记录来存储更新内容。
- Log-structured存日志,使用out-place-update-structure异地更新结构,会将更新的内容存到到新的位置,而不是覆盖
- Trees
- lock和latch的区别
- 为什么要有DBMS的磁盘管理。
- [数据库bufferpool]
- 2个主要策略方向
- 空间控制策略通过决定将 pages 写到磁盘的哪个位置,使得常常一起使用的 pages 能离得更近,从而提高 I/O 效率。
- 时间控制策略通过决定何时将 pages 读入内存,写回磁盘,使得读写的次数最小,从而提高 I/O 效率。
- 存储了什么数据?
- tuples
- indexes
- Sorting + Join Buffers
- Query Caches
- log bugffer
- Dictionary Caches
- 概念
- 与磁盘中的结构对应关系
- disk page —> frames 不考虑压缩情况的话,一般只是直接简单拷贝。
- [page directory] —> [pagetable]
- 缓冲池优化
- 操作系统缓存,一般不用操作系统缓存。Postgresql 是唯一一个有使用操作系统缓存的。
- 替换策略
- 重点解决问题
- 缓冲池污染,即大量全表扫描时,会把很多页都加载一遍。会导致真正需要使用的数据被替换掉。
- DBMS预读,导致加载的页不一定都是被用到
- LRU
- Clock(时钟置换算法,近似LRU)
- LRU-K ,mysql 的 bufferpool实现,就是使用LRU-K
- 重点解决问题
- 脏页回刷(Background Writing)
- 移除脏页的成本比一般页高,因为脏页还得回刷到磁盘上。而一般页直接废弃就可以。一般会使用后台定时刷.减少脏页的数量
- 2个主要策略方向
- access method - 数据结构
- 哈希表, 如 pagetable、page directory 自适应hash等。
- Trees 索引,数据、索引的存储结构。一般用B+tree In-place update structure
- 跳跃表
- LSM树 — out-place-update-structure异地更新结构
- radixTree go中的gin,路由匹配就是用radixTree
- trie 前缀树