什么是页💡
页,可以理解为文件系统中的block。作为磁盘和内存之间交互的基本单位。也就说,一次最少从磁盘中读取一页数据,一次也最少把一页内容刷到磁盘中。
为什么需要page呢?💡
其它,这个主要是因为局部性原理中的空间局部性,如果每次加载数据中的tuple,都从文件从读取一个tuple,这样效率会很低,因为磁盘的读写很慢。所以为了充分利用空间局部性(多读点,而不是用多少读多少),按page的级别进行加载和管理数据。
就比如OS 的文件系统通常将文件切分成 pages 进行管理一样。
有几个不同的 page 概念需要分清楚
- Hardware Page:通常大小为 4KB。
- OS Page: 通常大小为 4KB
- Database Page:(1-16KB) 4kB: sqllite, oracle 8KB: sqlserver/postgresql 16kB: mysql
这里涉及到一个问题,比如mysql的page,是16kB,而OS的page是4KB,也就是1个数据库的page的IO操作对应4个OS的page。在mysql页刷入磁盘时,需要进行4次的IO操作。可能会出现,2个OSpage后,操作系统宕机,导致数据库的page不完整。出现了数据的不完整性。为了解决这个问题,mysql使用了DoubleWrite
页的管理
pages 管理模块需要记录哪些 pages 已经被使用,而哪些 pages 尚未被使用。那么具体如何来记录和管理呢。
Heap File Organization
无序的页的集合。
支持增加改查 页。 大部分支持遍历。
首先,如果只有tuple都存在单文件。那边有个很简单的方案,每个tuple固定大小。根据偏移量来计算页的offset即可。但是大部分都是在不同文件。所以主要有2种方案:
链表(基本不用)
维护2个链表,一个free page list ,一个data page list.有点像bufferpool的处理
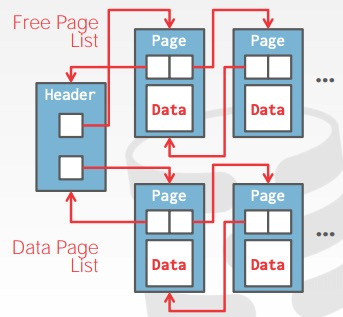
改进版本,双向链表
page directory页目录,标记哪些是没被使用过的

数据页的布局
header

- 页大小
- 校验和 checksum, 用于故障恢复使用,用来判断数据的完整性
- 数据库版本号
- 事务可见性
- 压缩信息
data
如何存储数据,主要有2个方案
Tuple-oriented(存数据)
[Log-structured]
Tuple layout
在 tuple-oriented 的 layout 中,DMBS 如何存储 tuple 本身呢。
一般也是 header + attribute data 的方式 .具体的细节有有一些不同。可以参考下 mysql行格式

header:
- Visibility Info (concurrency control):即 tuple 粒度的权限和并发控制
- Bit Map for NULL values
attribute data:
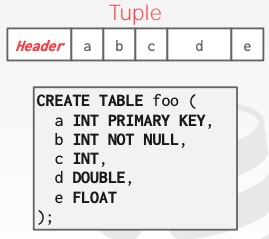
在 DBMS 层面上,由于它需要跟踪每一个 tuple,因此通常会给每个 tuple 赋予一个唯一的标识符(record identifier),通常这个标识符由 page_id + offset/slot 组成,有时候也会包含文件信息。这属于 DBMS 实现的细节,虽然它是唯一的,但 DBMS 可能随时修改它,因此 DBMS 上层的应用不应该依赖于它去实现自己的功能。
tuple storage:如何使用tuple来表示数据
本质上,一个tuple就是一串字节序列,DBMS有解码方案去解释这些字节序列。有点像C++,读到了一些字节序列,到底是Long ,还是时间格式,是根据数据类型来区分的。
比如,时间类型在底层也是存Long ,但是是指从1970年1月1日起的秒数或者微秒数来处理的。
浮点型,使用IEEE754标准,所以会有精度问题,比如 0.1 + 0.2 可能是等于0.2999999。
在数据库中,要精确的数据,一般都有具体的实现。如mysql 中的 decimal
1. typedef unsigned char NumericDigit;
2. typedef struct {
3. int ndigits; // # of Digits
4. int weight; // Weight of 1st Digit
5. int scale; // Scale Factor 因子
6. int sign; // Positive/Negative/NaN 正负
7. NumericDigit * digits; // Digit Storage
8. } numeric;溢出页 overflow page
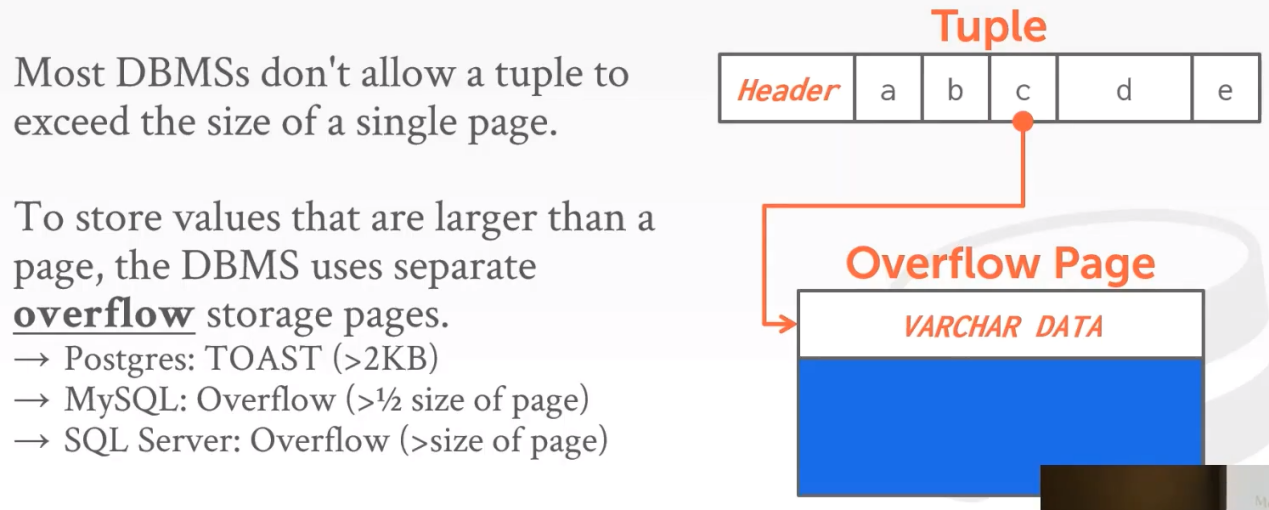
tuple的数据太大,导致真实数据太少。一般在tuple中,存指针。而真正的数据放在overflow page中。业务上来说,像文件等二进制数据,应该放在专门的存储服务中,而不是放在数据库中。
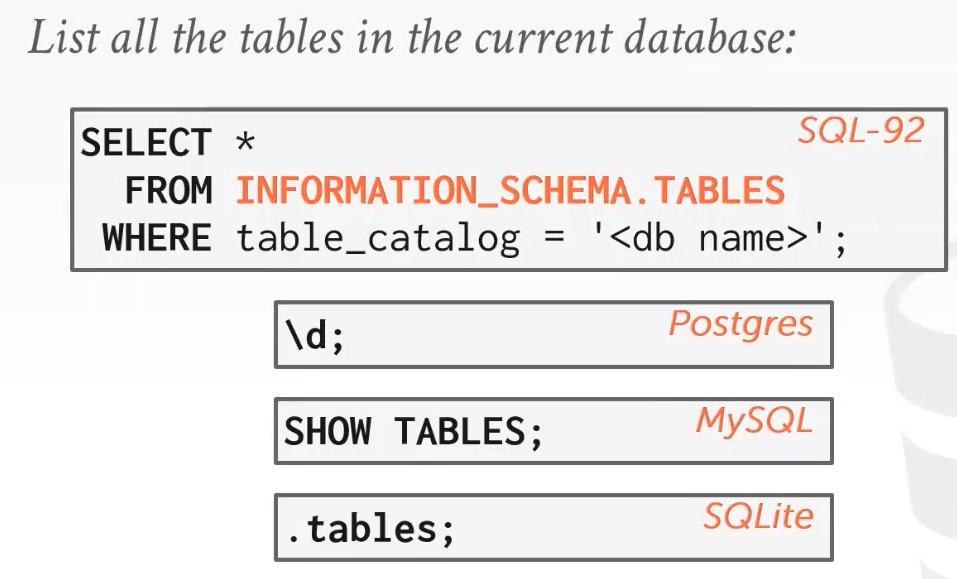
数据库的元数据怎么存储? 使用系统表
根据 SQL-92 标准,大部分数据库系统通过 INFORMATION_SCHEMA 把元数据暴露出来,数据库来查询这些数据库的元信息,但一般 DBMSs 都会提供更便捷的命令来查询这些信息。 比如mysql中,show tables;等

存储模式
WorkLoad
数据库的应用场景大体可以用两个维度来描述:操作复杂度和读写分布。
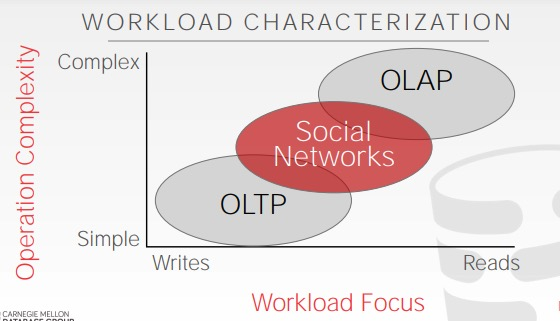
oltp: OLTP (事务分析处理)场景包含简单的读写语句,且每个语句都只操作数据库中的一小部分数据(常规操作,例如注册用户、添加商品到购物车),对于用户来说不会更新太多数据,一般就是更新自己的账户信息,自己的购物车信息。行存储
oltp: OLAP(联机分析处理),OLAP 主要处理复杂的,需要检索大量数据并聚合的操作(有点像数据科学、大数据处理、商务智能),这种场景下不会更新数据。这种操作一般是只读、会读取大量的数据、会扫描整张表。一般都是采用列存储,即一般都是使用列族数据库
HTAP: 混合事务分析处理,包含了OLTP和OLAP,一般中和了2种,都是都无法做到极致。