记录数据被修改后的样子💡
因为changebuffer是存在内存中的,万一机器重启,change buffer中的更改没有来得及更新到磁盘,就需要根据redolog来找回这些更新。
redo log里记录了数据页的修改以及change buffer新写入的信息。
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的,并且是事务的记录是顺序追加的,性能非常高(磁盘的顺序写性能逼内存的写性能差不了太多)。
InnoDB使用日志来减少提交事务时的开销。因为日志中已经记录了事务,就无须在每个事务提交时把缓冲池的脏块刷新(flush)到磁盘中。事务修改的数据和索引通常会映射到表空间的随机位置,所以刷新这些变更到磁盘需要很多随机IO。InnoDB假设使用常规磁盘,随机IO比顺序IO昂贵得多,因为一个IO请求需要时间把磁头移到正确的位置,然后等待磁盘上读出需要的部分,再转到开始位置。
InnoDB用日志把随机IO变成顺序IO。一旦日志安全写到磁盘,事务就持久化了,即使断电了,InnoDB可以重放日志并且恢复已经提交的事务。
logbuffer(内存)刷到文件系统,需要经过内核态
为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(即fsync()系统调用)
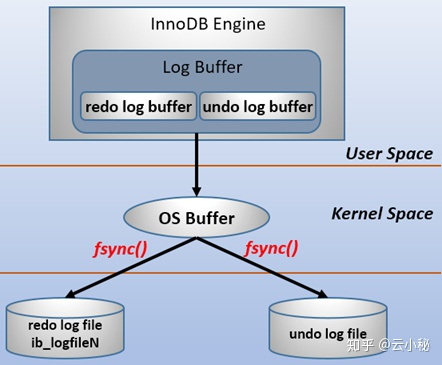
在此处需要注意一点,一般所说的log file并不是磁盘上的物理日志文件,而是操作系统缓存中的log file,既然都称为file了,应该已经属于物理文件了。所以在本文后续内容中都以os buffer或者file system buffer来表示官方手册中所说的Log file,然后log file则表示磁盘上的物理日志文件,即log file on disk。另外,之所以要经过一层os buffer,是因为open日志文件的时候,open没有使用O_DIRECT标志位,该标志位意味着绕过操作系统层的os buffer,IO直写到底层存储设备。不使用该标志位意味着将日志进行缓冲,缓冲到了一定容量,或者显式fsync()才会将缓冲中的刷到存储设备。使用该标志位意味着每次都要发起系统调用。比如写abcde,不使用o_direct将只发起一次系统调用,使用o_object将发起5次系统调用
刷盘策略
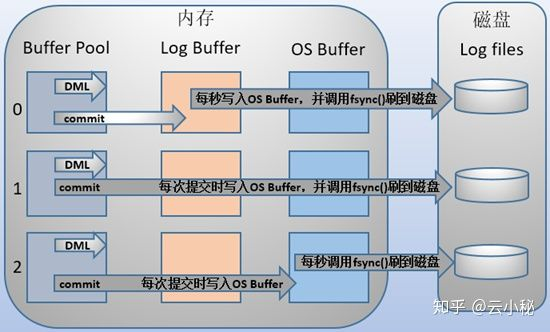
在主从复制结构中,要保证事务的持久性和一致性,每次提交事务都写入二进制日志和事务日志,并在提交时将它们刷新到磁盘中,需要对日志相关变量设置为如下(双1):
- 如果启用了二进制日志,则设置sync_binlog=1,即每提交一次事务同步写到磁盘中。
- 总是设置innodb_flush_log_at_trx_commit=1,即每提交一次事务都写到磁盘中。
redo log就是为了保证事务的持久性。因为change buffer是存在内存中的,万一机器重启,change buffer中的更改没有来得及更新到磁盘,就需要根据redolog来找回这些更新。 优点是减少磁盘I/O次数,即便发生故障也可以根据redo log来将数据恢复到最新状态。 缺点是会造成内存脏页,后台线程会自动对脏页刷盘,或者是淘汰数据页时刷盘,此时收到的查询请求需要等待,影响查询。