索引,排好序的查找结构
索引的目的在于提高查询效率,可以类比字典、 火车站的车次表、图书的目录等。 本质上,是一种排好序的快速查找数据结构。
在mysql中,需要用于查找、排序、聚合。即 where/join 或者oder by 、group by等
优势:
- 提高数据检索效率,降低数据库IO成本
- 降低数据排序的成本,降低CPU的消耗
劣势:
- 索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以也需要占用内存
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。 因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段, 都会调整因为更新所带来的键值变化后的索引信息
索引分类
数据结构角度
- B+树索引(
PRIMARY KEY,UNIQUE,INDEX, andFULLTEXT) - Hash索引, meory引擎 自适应hash
- Full-Text全文索引、 倒序list
- R-Tree索引,(地理位置相关 geo)
从物理存储角度
- 聚集索引(clustered index)innodb
- 非聚集索引(non-clustered index),也叫辅助索引(secondary index)myisam
聚集索引和非聚集索引都是B+树结构
从逻辑角度
- 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
- 普通索引或者单列索引:每个索引只包含单个列,一个表可以有多个单列索引
- 多列索引(复合索引、联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
- 唯一索引或者非唯一索引
- 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。 MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
索引数据结构
二叉树 xx
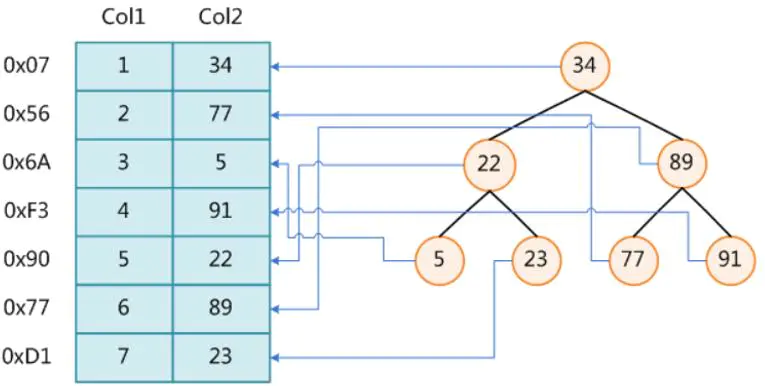
不适合用作当作索引,数据量庞大的话,二叉树的层数会很大,查找效率固然也很慢。顺序插入,退化成了链表
红黑树xx
存储大数据量,树的高度不可控, 数量越大,树的高度越高;500w行数据,2的n次方=500w数据量, n是树的高度,也就是查询次数
B树 xx

本质是多路二叉树;叶节点具有相同的深度,叶节点的指针为空;所有索引元素不重复;节点中数据索引从左到右依次递增的
B+树
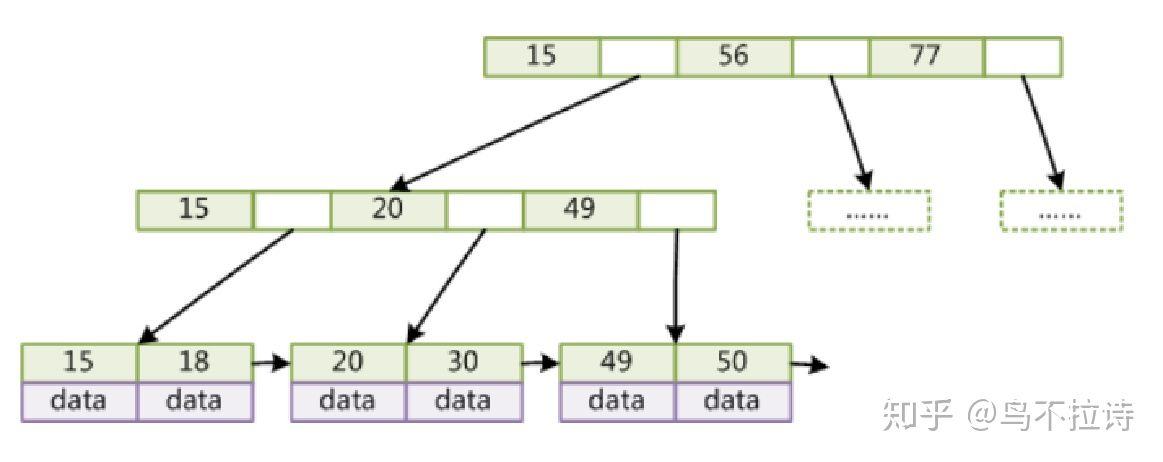
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
- 只有叶子节点带有卫星数据data(索引元素所指向的数据记录)
为什么Mysql索引要用B+树不是B树?
- 用B+树不用B树考虑的是IO对性能的影响,B树的每个节点都存储数据,而B+树只有叶子节点才存储数据,所以查找相同数据量的情况下,B树的高度更高,IO更频繁。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。
- 其中在MySQL底层对B+树进行进一步优化:在叶子节点中是双向链表,且在链表的头结点和尾节点也是循环指向的
用B+树,引发的一些问题
先总结下,B+树的特点
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
- 只有叶子节点带有卫星数据data(索引元素所指向的数据记录)
问题:
- 聚集索引与非聚集索引(即叶子节点存储的data到底是什么?)
叶子结点存放的是数据还是指向数据的内存地址。
- 为什么建议自增ID?
- bigint 存储空间少,比较大小快。不建议用uuid。或者可使用 分布式id。
- 本质是多路多叉树,避免节点分裂和重新平衡。
- 为什么InnoDB表必须有主键,并且推荐使用证型的自增主键??
InnoDB引擎使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
- 如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页,这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
- 如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置。此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
- 为什么非主键索引结构叶子节点存储的是主键值(一致性和节省存储空间,如果普通索引中就可以得到查询的记录,称为索引覆盖,否则需要进行回表操作)
- 自增主键为什么不是连续的?
- 唯一键冲突是导致自增主键id
- 事务回滚也会产生类似的现象
- 批量申请自增id策略,预申请
- 删除主键索引和普通索引的区别?
- 如果删除,新建主键索引,会同时去修改普通索引对应的主键索引,性能消耗比较大
- 删除重建普通索引貌似影响不大,不过要注意在业务低谷期操作,避免影响业务
主键索引、普通索引和联合索引的存储结构?
假设,一个表中有id (主键)、name(普通索引)、name-age联合索引
主键索引:
非叶子节点,是 主键值进行排序
叶子节点,存储的是数据
普通索引:
非叶子节点,是 索引字段进行排序.
叶子节点,存储的是主键值。
联合索引(最左匹配原则):

非叶子节点,由多个字段组成,进行排序
叶子节点,存储的是主键值
适用场景
- 主键自动建立唯一索引
- 频繁作为查询条件的字段
- 查询中与其他表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,高并发下倾向创建组合索引
- 查询中排序的字段,排序字段通过索引访问大幅提高排序速度
- 查询中统计或分组字段
改进空间
资料
MySQL :: MySQL 8.0 Reference Manual :: 8.3.1 How MySQL Uses Indexes