link: 凤凰架构
待办列表
常青笔记
- 分布式写一致性级别(All、Quorum机制、One、Any)
- 多副本是分布式中的重要问题,本质上分布式就是解决多副本的同步问题、共识问题。
- 数据同步是直接同步原始数据,状态转移。以同步为代表的数据复制方法。需要每个节点都参与同步,导致可用性太差。
- 主流做法,是操作转移。类型react中的增量操作。分布式一致性的解决方案是状态机复制来达到的。
- Quorum机制 (多数派):分布式节点多余一半完成了状态转换,就认为存储成功。
分布2式算法种类
拜占庭问题
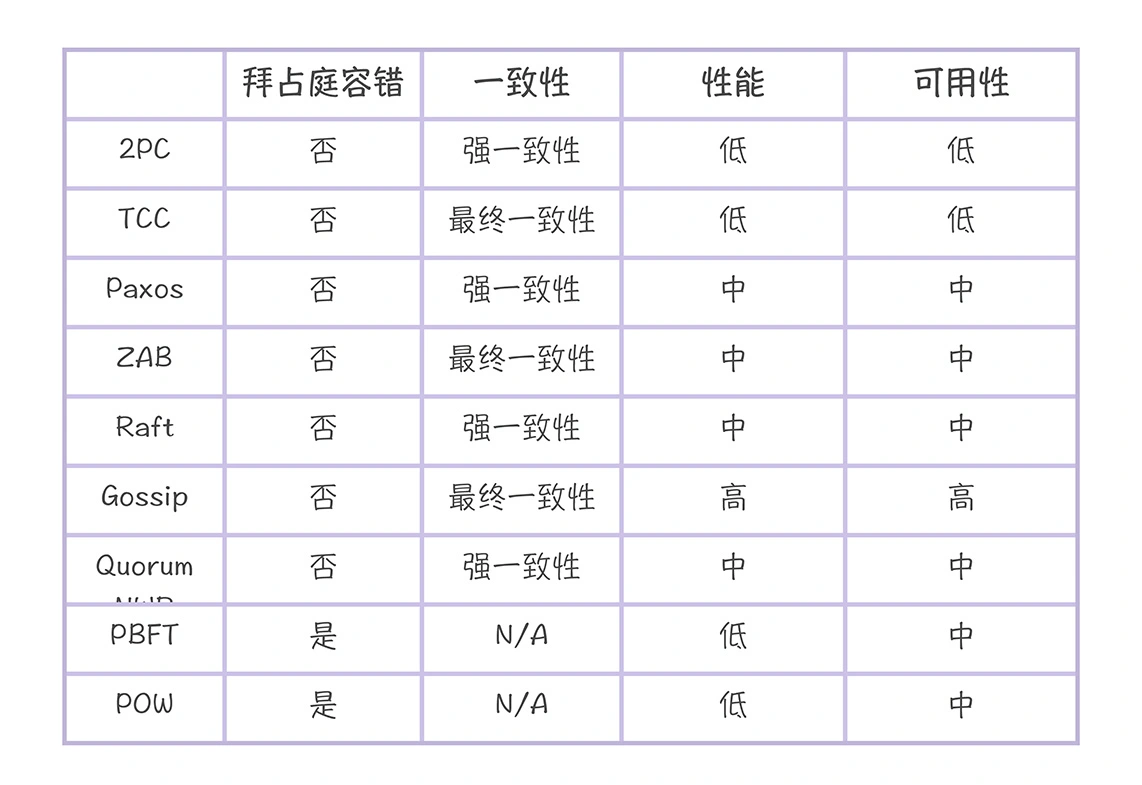
一般而言,在可信环境(比如企业内网)中,系统具有故障容错能力就可以了,常见的算法有二阶段提交协议(2PC)、TCC(Try-Confirm-Cancel)、Paxos 算法、ZAB 协议、Raft 算法、Gossip 协议、Quorum NWR 算法。而在不可信的环境(比如有人做恶)中,这时系统需要具备拜占庭容错能力,
常见的拜占庭容错算法有 POW 算法、PBFT 算法。
一致性
在 CAP 定理中,CAP 中的强一致性(也就是 C)是指原子一致性(也就是线性一致性)。其中,Paxos、Raft 能实现线性一致性,而 ZooKeeper 基于读性能的考虑,它通过 ZAB 协议提供的是最终一致性
在需要系统状态的一致性时,你可以考虑采用二阶段提交协议(2PC)、TCC。在需要数据访问是的强一致性时,你可考虑 Raft 算法。在可用性优先的系统,你可以采用 Gossip 协议来实现最终一致性,并实现 Quorum NWR 来提供强一致性。
可用性:
可用性说的是任何来自客户端的请求,不管访问哪个非故障节点,都能得到响应数据,但不保证是同一份最新数据,可用性强调的是服务可用。
一般来讲,采用 Gossip 协议实现最终一致性系统,它的可用性是最高的,因为哪怕只有一个节点,集群还能在运行并提供服务。其次是 Paxos 算法、ZAB 协议、Raft 算法、Quorum NWR 算法、PBFT 算法、POW 算法,它们能容忍一定数节点故障。
最后是二阶段提交协议、TCC,只有当所有节点都在运行时,才能工作,可用性最低。
性能
一般来讲,采用 Gossip 协议的 AP 型分布式系统,具备水平扩展能力,读写性能是最高的。
其次是 Paxos 算法、ZAB 协议、Raft 算法,因为它们都是领导者模型,写性能受限于领导者,读性能取决于一致性实现。
最后是二阶段提交协议和 TCC,因为在实现事务时,需要预留和锁定资源,性能相对低。
分布式一致性
- 如何保证数据的可靠性?即存储的不丢失?但是多副本。即有多个机器,存储同一份数据,这涉及到如何保证数据的一致性问题。
- 首先,容易想到的是 数据同步。每当数据有变化,把变化情况在各个节点间的复制视作一种事务性的操作。即每个节点都同步成功才算成功。如2PC、3PC协议。即通过分布式事务来保证数据的同步一致性。可靠性与可用性的矛盾造成了增加机器数量反而带来可用性的降低。以同步为代表的数据复制方法,被称为状态转移(State Transfer)
- 缺点: 性能差,需要每个节点都成功。可用性差。
- 主流做法,平衡了可用性和可靠性。数据复制方法是以操作转移(Operation Transfer)为基础。操作
解决方案
分布式一致性的一般解决方案按状态机复制。通俗的说,就是每个操作都是一条操作日志。
一致性模型
弱一致性模型
- DNS
- Gossip
强一致性模型
主要思路,是全部节点都需要同意,还是多半即可(多数派模型)
- 同步
- MYSQL的主从复制模型,同步复制,即从节点写入成功才算成功。
- 异步复制,即
- 2PC/3PC/TCC等
分布式共识算法与演进
共识
共识(Consensus)与一致性(Consistency)的区别:
由于翻译的关系,很多中文资料把 Consensus 同样翻译为一致性,导致网络上大量的“二手中文资料”将这两个概念混淆起来,如果你在网上看到“分布式一致性算法”,应明白其指的其实是“Distributed Consensus Algorithm”。
- 共识:各节点就指定值(Value)达成共识,而且达成共识后的值,就不再改变了。共识是指达成一致性的方法与过程
- 一致性:是指写操作完成后,能否从各节点上读到最新写入的数据,如果立即能读到,就是强一致性,如果最终能读到,就是最终一致性。一致性是指数据不同副本之间的差异
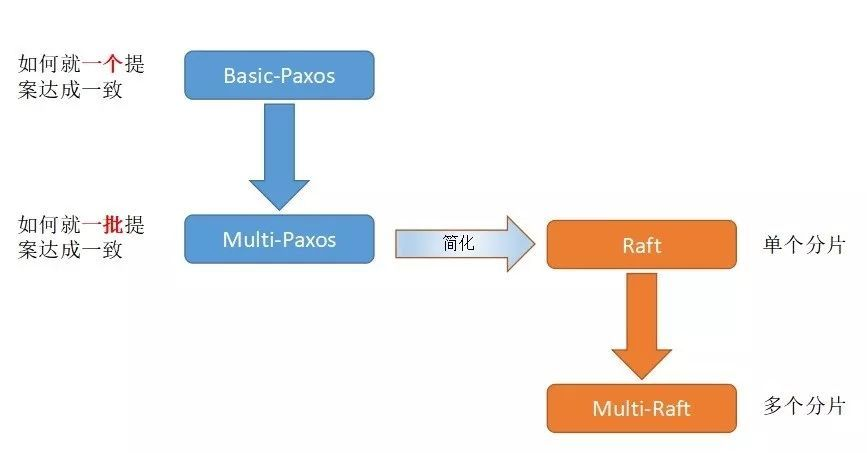
paxos的算法演进
.png)
Paxos
缺点:
- rpc调用次数多
- 活锁问题。即交替进行提案。
- 为什么需要prepare阶段?就是因为并发问题,即多个purposer
MultiPaxos
简化版本:
- 选举 + 复制。 选举,确定出 leader。
- 允许多提案者
- 领导者选举权, 任意副本,日志提交试用异步的commit消息。日志连续性,可以允许空洞。
Raft
- 唯一的leader,领导者选举权,需要最新提的日志的副本。日志需要保证连续,日志提交需要靠推进commit index
拆分成3个子问题 - 领导者选举
- 日志复制
- Safety 安全,恢复
角色: - leader(领导者) 2. Follower(更随者) 3. Candidate(参与者)
角色是动态变化的,而不是固定的。
MultiPaxos 、ZAB、Raft 为什么是等价算法?
核心的原理一样
- 通过随机超时来实现无活锁的选主过程。
- 通过主节点来发起写操作。同时只有1个主节点。
- 通过心跳来检测存活性
- 通过Quorum机制来保证一致性
具体细节上可以有差异:
譬如是全部节点都能参与选主,还是部分节点能参与,
譬如Quorum中是众生平等还是各自带有权重,
譬如该怎样表示值的方式
MultiPaxos 无需要求日志顺序,达成共识后,这个值不能变。
ZAB和Raft: “一切以领导者为准”的强领导者模型和严格按照顺序提交日志是一样的。
ZAB 协议要实现操作的顺序性,而 Raft 的设计目标,不仅仅是操作的顺序性,而是线性一致性,这两个目标,都决定了它们不能允许日志不连续,要按照顺序提交日志,那么,它们就要通过上面的方法实现日志的顺序性,并保证达成共识(也就是提交)后的日志不会再改变。
为什么在 Multi-Paxos、Raft 中需要状态机呢?
Multi-Paxos、Raft 都是共识算法,而共识算法是就一系列值达成共识的,达成共识后,这个值就不能改了。但有时候我们是需要更改数据的值的,比如 KV 存储,我们肯定需要更改指定 key(比如 X)对应的值,这时我们就可以通过状态机来解决这个问题。
比如,如果你想把 X 的值改为 7,那你可以提议一个新的指令“SET X = 7”,当这个指令被达成共识并提交到状态机后,你查询到的值就是 7 了,也就成功修改了 X 的值。