redis-消息队列
Tip redis-stream,消息队列的集大成者💡
- 支持了消息的持久化,
- ack确认机制,penginglist存储已读取待确认,保证了消息的可靠性消费。
- 支持消息多播,同一个消息,给多个消费/消费组消费
- 支持阻塞读取消息,避免浪费cpu资源,一直循环获取。
与专业消息队列的差距💡
- 消息可能丢失, 生产者要重试可避免, 消费者ack确认机制,可避免。但是中间件,
1.1 可能存在AOF最后1秒没刷盘情况。
1.2 存在主从复制集群问题。- 消息堆积能力不强,数据存储在内存中。容易导致oom。而专业消息队列,是存储在磁盘中
redis-消息队列💡
关于 Redis 是否适合做消息队列,业界一直是有争论的。很多人认为,要使用消息队列,就应该采用 Kafka、RabbitMQ 这些专门面向消息队列场景的软件,而 Redis 更加适合做缓存。
关于是否用 Redis 做消息队列的问题,不能一概而论,我们需要考虑业务层面的数据体量,以及对性能、可靠性、可扩展性的需求。如果分布式系统中的组件消息通信量不大,那么,Redis 只需要使用有限的内存空间就能满足消息存储的需求,而且,Redis 的高性能特性能支持快速的消息读写,不失为消息队列的一个好的解决方案。
| 发布/订阅 | 基于List | 基于zset | 基于stream | |
|---|---|---|---|---|
| 消息保持顺序 | public/subscribe | lpush/rpop | zadd/zrangebyscore | xadd/xread |
| 阻塞读取 | - | brpop | 无阻塞读取命令 | xread block |
| 消息可靠性 | 重启可能丢失 | 使用brpoplush命令 | 使用penginglist存储已读取,未确认消息。ack确认机制,避免消息丢失 | |
| 持久化 | 不支持持久化, 发后既往,不支持消费历史数据 | 支持 | 支持 | 支持 |
| 消费组消费 | 支持主题订阅 | 不支持 | 不支持 | 支持,xgroup |
| 使用场景 | 较少使用 | redis5.0前版本,消息总量小 | 一般用于延迟队列 | 使用redis消息队列方案的方案 |
| 消息多播 | 支持 | 不支持 | 不支持 | 支持 |
发布订阅模式
命令
技巧💡
- subscribe channel 普通订阅
- publish channel message 消息推送
- psubscribe pattern 主题订阅
psubscribe log_* 订阅log_前缀的主题
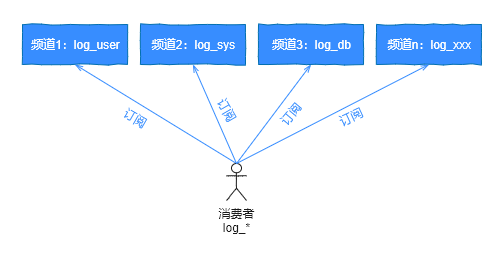
缺点:
- 无法持久化保存消息,如果 Redis 服务器宕机或重启,那么所有的消息将会丢失;
- 发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息
- 当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过 32M 或者是 60s 内持续保持在 8M 以上,消费端会被强行断开,这个参数是在配置文件中设置的,默认值是
client-output-buffer-limit pubsub 32mb 8mb 60
代码
/**
* 消费者
*/
public static void consumer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 接收并处理消息
jedis.subscribe(new JedisPubSub() {
@Override
public void onMessage(String channel, String message) {
// 接收消息,业务处理
System.out.println("频道 " + channel + " 收到消息:" + message);
}
}, "channel");
}
/**
* 主题订阅
*/
public static void pConsumer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 主题订阅
jedis.psubscribe(new JedisPubSub() {
@Override
public void onPMessage(String pattern, String channel, String message) {
// 接收消息,业务处理
System.out.println(pattern + " 主题 | 频道 " + channel + " 收到消息:" + message);
}
}, "channel*");
}
/**
* 生产者
*/
public static void producer() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 推送消息
jedis.publish("channel", "Hello, channel.");
}
redis-list
redis-list实现mq💡
- 生产者使用lpush,保存数据到list
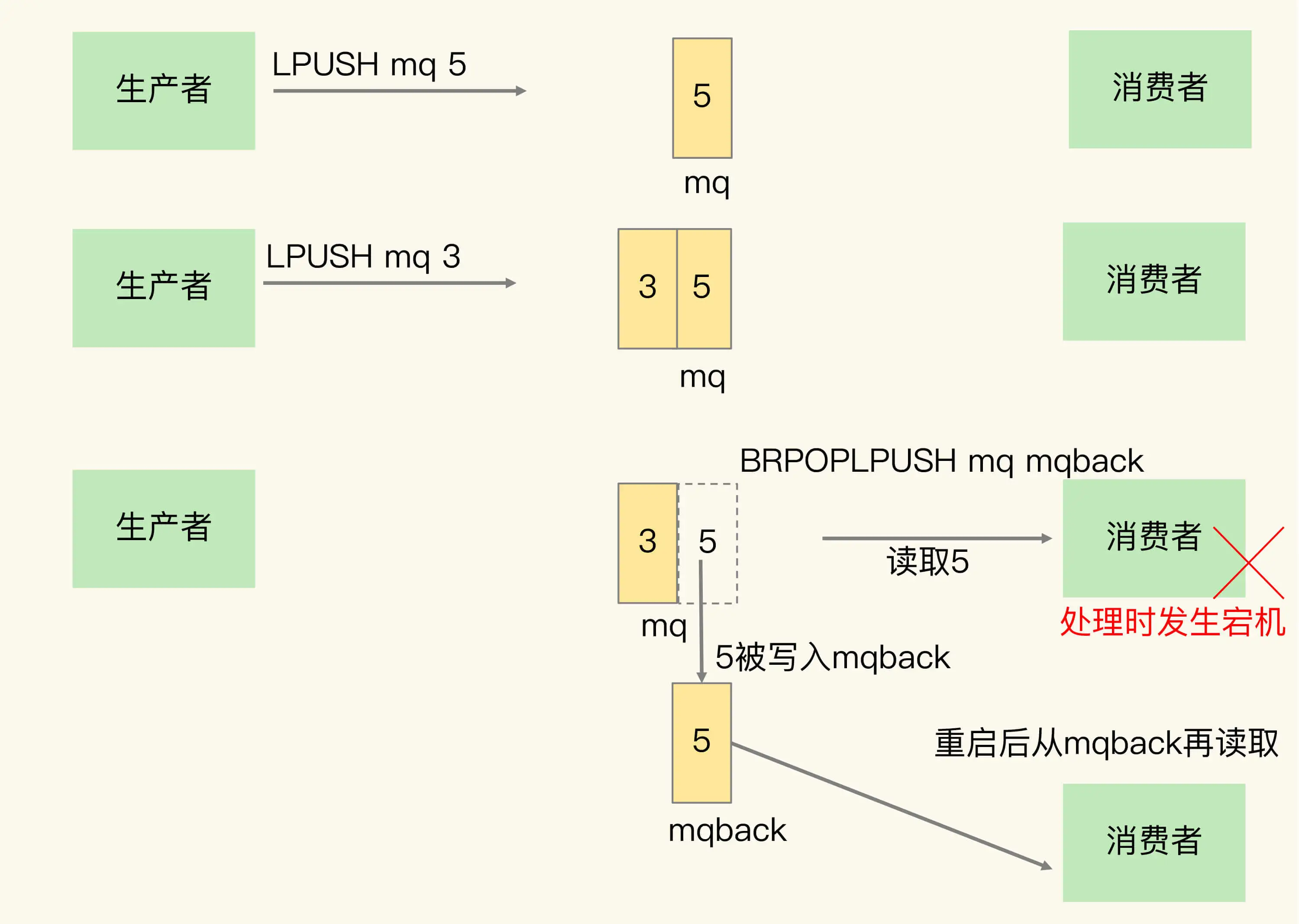
- 生产者使用lpush,将消息push到 redis的list中
- 消费者,不断使用brpoplpush 命令,获取消息,
- 使用
lpop,需要一直轮询可以使用。导致消费者程序的 CPU 一直消耗在执行 RPOP 命令上,带来不必要的性能损失。 BRPOP命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据- 推荐使用,BRPOPLPUSH,消费者程序使用 BRPOPLPUSH 命令读取消息“5”,同时,消息“5”还会被 Redis 插入到 mqback 队列中。避免处理过程中,消费者宕机,消息丢失
List 优点:
- 使用
- 消息可以被持久化,借助 Redis 本身的持久化(AOF、RDB 或者是混合持久化),可以有效的保存数据;
- 消费者可以积压消息,不会因为客户端的消息过多而被强行断开。
List 缺点:
- 消息不能被重复消费,一个消息消费完就会被删除;
- 没有主题订阅的功能。
redis-zset
实现思路和 List 相同也是利用 zadd 和 zrangebyscore 来实现存入和读取。一般是score存储时间戳,用来实现延迟队列
ZSet 优点:
- 支持消息持久化;
- 相比于 List 查询更方便,ZSet 可以利用 score 属性很方便的完成检索,而 List 则需要遍历整个元素才能检索到某个值。
ZSet 缺点:
- ZSet 不能存储相同元素的值,也就是如果有消息是重复的,那么只能插入一条信息在有序集合中;
- ZSet 是根据 score 值排序的,不能像 List 一样,按照插入顺序来排序;
- ZSet 没有向 List 的 brpop 那样的阻塞弹出的功能
redis-stream redis消息队列实现最优方案
技巧💡
Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它借鉴了 Kafka 的设计思路,它支持消息的持久化和消息轨迹的消费,支持 ack确认消息的模式,让消息队列更加的稳定和可靠
命令
- xadd 添加消息;
- xlen 查询消息长度;
- xdel 根据消息 ID 删除消息;
- del 删除整个 Stream;
- xrange 读取区间消息
- xread 读取某个消息之后的消息。
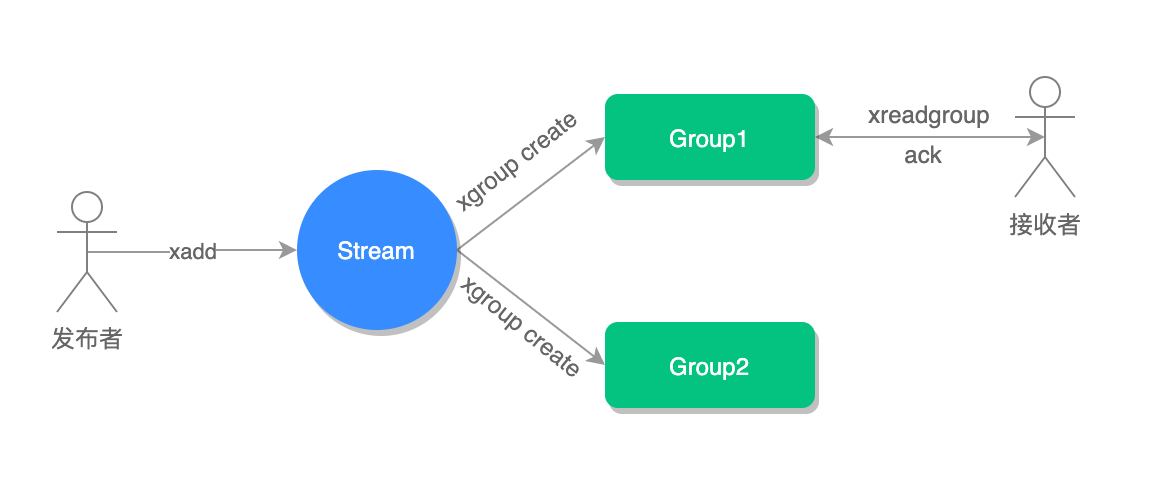
xread count 1 block 0 streams mq $, block 0 参数表示是阻塞读。 - xgroup, 创建消费组。
xgroup create stream-key group-key ID - xreadgroup, 消费者读取消息。
xreadgroup group group-key consumer-key streams stream-key - xpengding, 查询每个消费组内所有消费者已读取但尚未确认的消息
- xack, 消息ack确认。
xack key group-key ID [ID …]
与专业消息队列的差异
^84080d
专业的消息队列包括:
-
RabbitMQ
-
Kafka
一个专业的消息队列,必须要满足两个条件: -
消息不丢
-
消息可堆积
消息不丢

生产者:消息发送失败或发送超时,这两种情况会导致数据丢失,可以使用重试来解决。不依赖消息中间件,需要业务实现。
消费者:消费者存在读取消息未处理完就异常宕机了,消费者要还能重新读取消息。Stream和其他消息中间件都能做到。
队列中间件:中间件要保证数据不丢失。 Redis 在以下 2 个场景下,都会导致数据丢失:
- AOF 持久化配置为每秒写盘,Redis 宕机时会存在丢失最后1秒数据的可能
- 主从复制的集群,主从切换时,从库还未同步完成主库发来的数据,就被提成主库,也存在丢失数据的可能。
基于以上原因可以推断出,Redis 本身的无法保证严格的数据完整性。
专业队列如何解决数据丢失问题:
RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时一般是部署一个集群。生产者在发布消息时,队列中间件通常会写「多个节点」,以此保证消息冗余。这样一来,即便其中一个节点挂了,集群也能的数据不丢失
消息堆积
因为 Redis 的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致 Redis 的内存持续增长,如果超过机器内存上限,就会面临 OOM 的风险。
所以,Redis 的 Stream 提供了可以指定队列最大长度的功能,就是为了避免这种情况发生。
但 Kafka、RabbitMQ 这类消息队列就不一样了,它们的数据都会存储在磁盘上,磁盘的成本要比内存小得多,当消息积压时,无非就是多占用一些磁盘空间,磁盘相比于内存在面对积压时能轻松应对
资料
15 消息队列的考验:Redis有哪些解决方案?
25 消息队列的其他实现方式
Redis 高级特性 Redis Stream使用 - 金色旭光 - 博客园