技巧💡
- 基于事件模式的IO模型。非阻塞IO
- 几乎所有的网络连接都会经过
accept: 连接
read: 读取请求内容
decode: 解码
compute: 业务处理
encode: 编码
send: 发送,回复内容
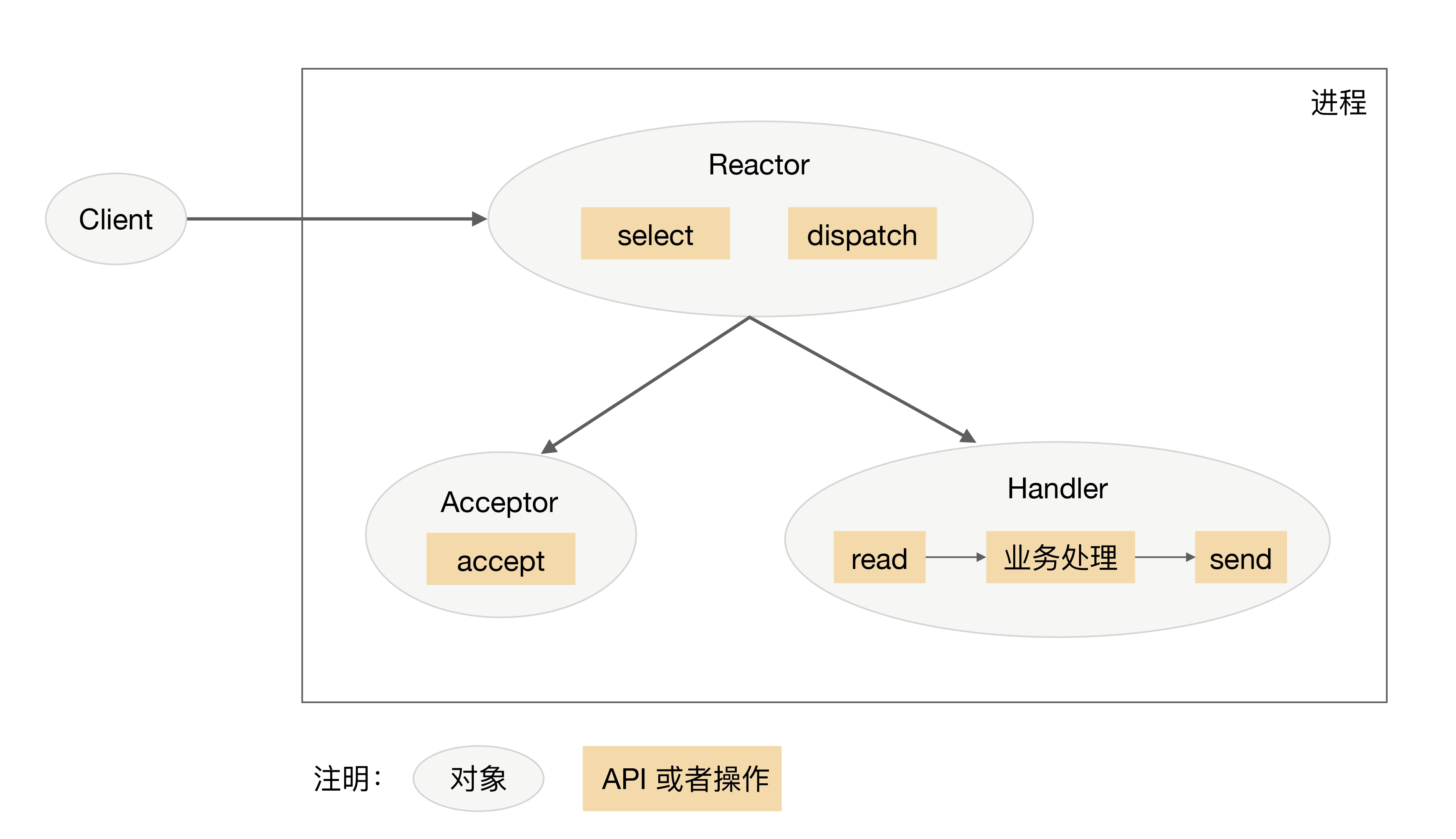
reactor💡
reactor, I/O 多路复用结合线程池。
事件反应,即来了一个事件我就有相应的反应。I/O 多路复用统一监听事件,收到事件后分配(Dispatch)给某个进程/线程。
Reactor 模式的核心组成部分包括 Reactor 和处理资源池(进程池或线程池),其中 Reactor 负责监听和分配事件,处理资源池负责处理事件
发展史
提示
- 单线程,一般阻塞->多线程,一般阻塞(一条连接一线程)->线程池(减少线程创建销毁开销)->reactor(更小粒度的线程)
- 所谓更小的粒度的线程是指,传统的多线程是一个连接一个线程,粒度太大,比如可以把一个连接继续细分成三个步骤:read,process,send三个步骤,每个步骤占一个线程,处理完后交给主线程调度,进入下一个处理模块
BIO
这种模型由于IO在阻塞时会一直等待,因此在用户负载增加时,性能下降的非常快。
BIO + 单线程
while(true){
socket = accept();
handle(socket)
}服务器用一个while循环,不断监听端口是否有新的套接字连接,如果有,那么就调用一个处理函数处理。最大问题是无法并发,效率太低,如果当前的请求没有处理完,那么后面的请求只能被阻塞,服务器的吞吐量太低。
BIO + 多线程 (经典的: connection per thread)
while(true){
socket = accept();
new thread(socket);
}资源要求太高,系统中创建线程是需要比较高的系统资源的,如果连接数太高,系统无法承受,而且,线程的反复创建-销毁也需要代价。(就算用线程池,也是治标不治本。)
reactor模式(基于事件驱动的非阻塞IO)
采用基于事件驱动的设计,当有事件触发时,才会调用处理器进行数据处理
在netty中,reactor是基于epollo或者select 进行多路复用。
#todo/continue epollo模型
可以服务器采取的并发模型的关键设计点:
- 服务器如何管理连接。accept
- 服务器如何处理请求 . read —> decode —> compute(业务处理) —> encode —> send
Reactor 模式的核心组成部分包括 Reactor 和处理资源池(进程池或线程池),其中
-
Reactor 负责监听和分配事件,
-
处理资源池负责处理事件。
reactor可以单个可以多个,处理资源池,可以是单线程,多线程。则两两组合。可以有 -
单 Reactor 单进程 / 线程。
-
单 Reactor 多线程。
-
多 Reactor 多进程 / 线程。
因为 多Reactor 单线程,实现比 单 Reactor 单进程,又复杂又没什么性能优势。所以基本上没使用。
单 Reactor 多进程, 这个实现复杂。
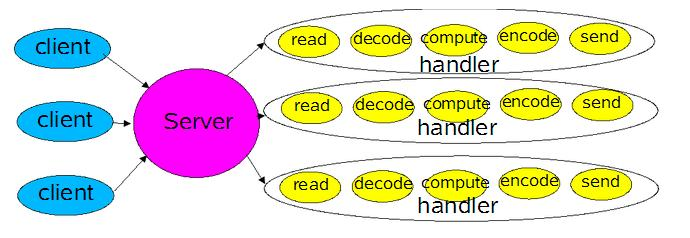
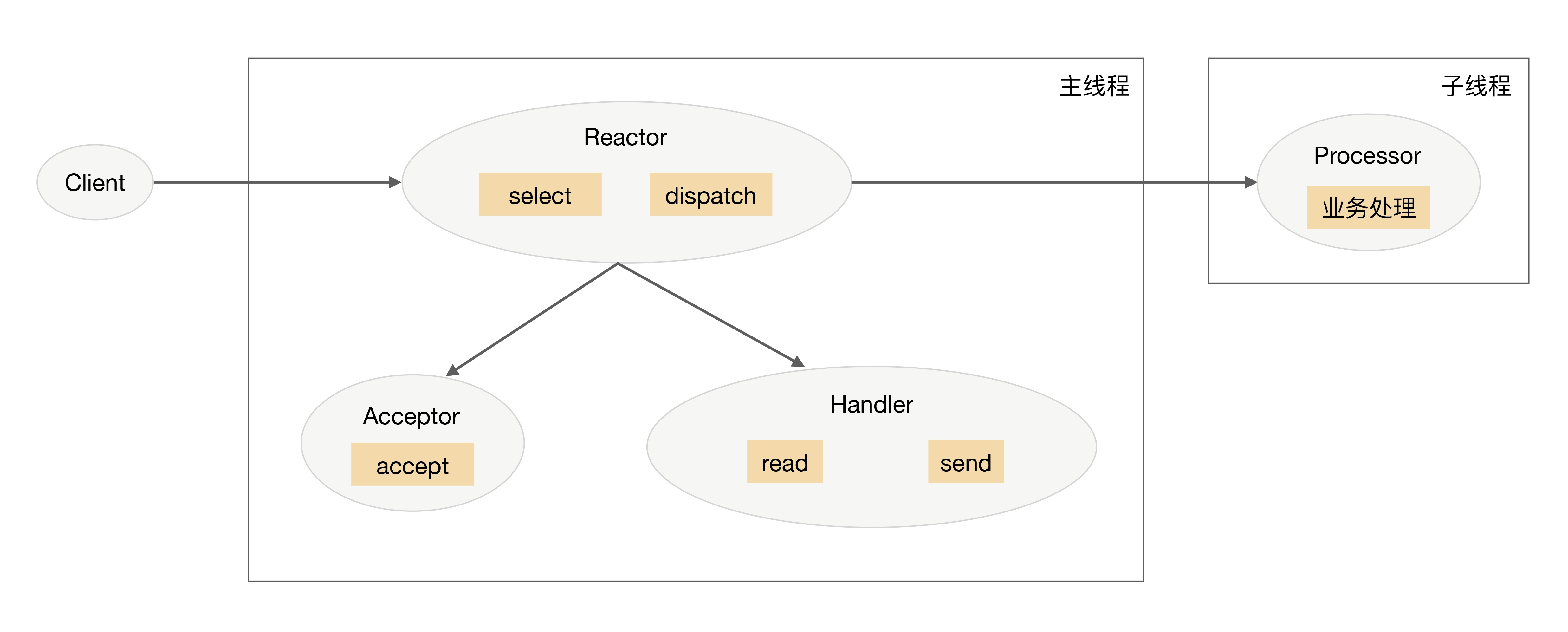
单 Reactor 单进程 / 线程(redis早期版本)
连接,IO事件等都在一个线程。
- Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发。
- 如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件。
- 如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler(第 2 步中创建的 Handler)来进行响应。
- Handler 会完成 read-> 业务处理 ->send 的完整业务流程
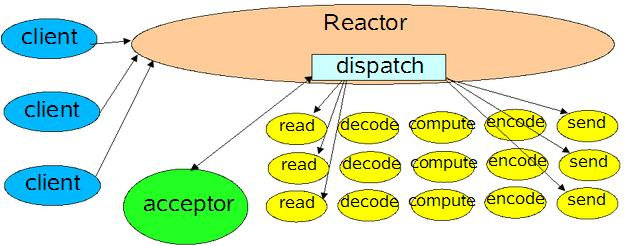
单 Reactor 多线程,(使用多线程处理业务逻辑)
将decode、compute、encode等处理器的执行放入线程池,多线程进行业务处理。但Reactor仍为单个线程。
Redis 6.0(单 Reactor 多线程模型)进行了优化,引入了 IO多线程,把读写请求数据的逻辑,用多线程处理,提升并发性能
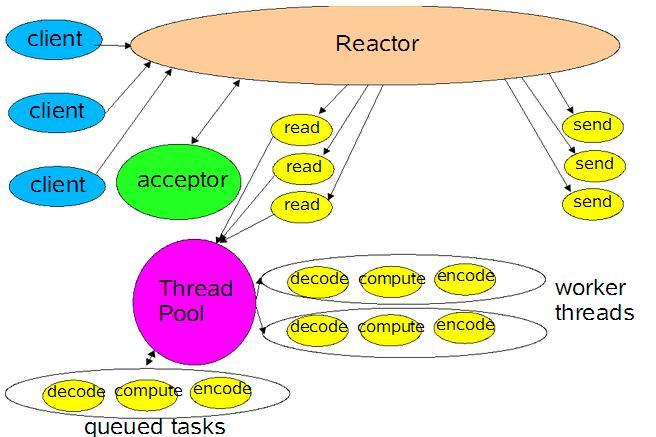
多reactor多线程/进程 (主从reactor模式,对于多个CPU的机器,为充分利用系统资源,将Reactor拆分为两部分)
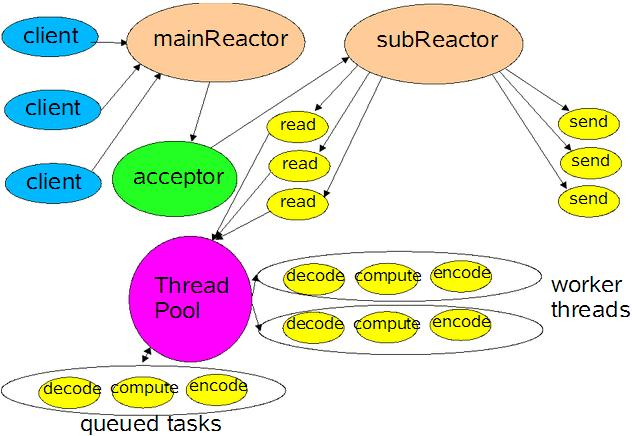
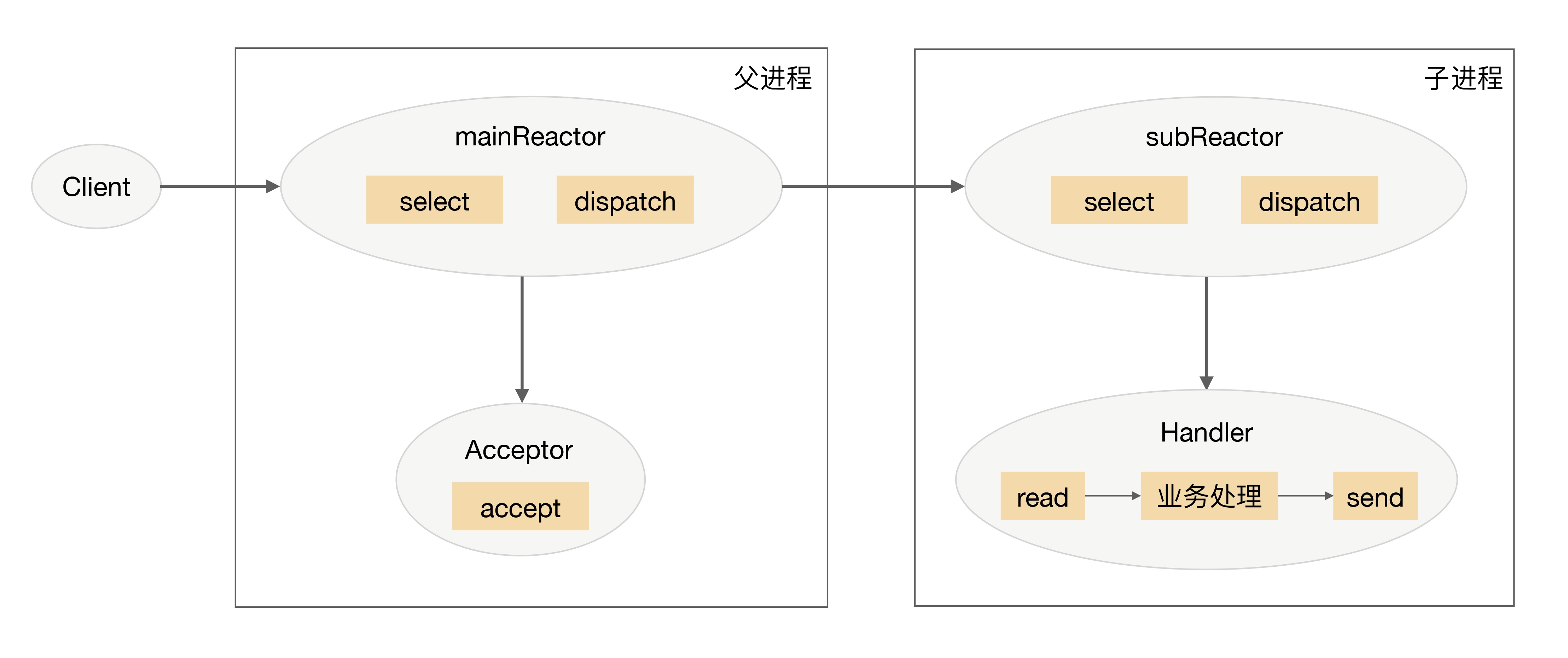
mainReactor负责监听连接,accept连接给subReactor处理,为什么要单独分一个Reactor来处理监听呢?因为像TCP这样需要经过3次握手才能建立连接,这个建立连接的过程也是要耗时间和资源的,单独分一个Reactor来处理,可以提高性能。
详细流程:
- 父进程中 mainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 接收,将新的连接分配给某个子进程。
- 子进程的 subReactor 将 mainReactor 分配的连接加入连接队列进行监听,并创建一个 Handler 用于处理连接的各种事件。
- 当有新的事件发生时,subReactor 会调用连接对应的 Handler(即第 2 步中创建的 Handler)来进行响应。
- Handler 完成 read→业务处理→send 的完整业务流程。
案例:
- Nginx:多 Reactor 多进程模型。主Reacotr不处理网络IO,只用来初始化 socket,由 Wroker子进程 accept 连接,之后这个连接的所有处理都在子进程中完成。每个Wroker进程是一个独立的单Reacotr单线程模型。
- Netty:多 Reactor 多线程模型。主Reacotr只负责建立连接,然后把建立好的连接给从Reactor,从Reactor负责IO读写。
- Kafka:多 Reactor 多线程模型。但因为Kafka主要与磁盘IO交互,因此真正的读写数据不是从Reactor 处理的,而是有一个worker线程池,专门处理磁盘IO,从Reactor负责网络IO,然后把任务交给worker线程池处理。
rocketmq中的1+N+M1+M2
笔记
- 1个Acceptor
- N(3)个处理IO事件
- M1(8)个线程 编解码器
- M2, 业务线程,即compute步骤
- 一个 Reactor 主线程(eventLoopGroupBoss)负责监听 TCP网络连接请求,
- 建立好连接后丢给Reactor 线程池(eventLoopGroupSelector,即为上面的“N”,源码中默认设置为3),它负责将建立好连接的socket 注册到 selector上去(RocketMQ的源码中会自动根据OS的类型选择NIO和Epoll,也可以通过参数配置),然后监听真正的网络数据。
- 拿到网络数据后,再丢给Worker线程池(defaultEventExecutorGroup,即为上面的“M1”,源码中默认设置为8)。为了更为高效的处理RPC的网络请求,这里的Worker线程池是专门用于处理Netty网络通信相关的(包括编码/解码、空闲链接管理、网络连接管理以及网络请求处理)。而
- 处理业务操作放在业务线程池中执行,即为”M2”,根据 RomotingCommand 的业务请求码code去processorTable这个本地缓存变量中找到对应的 processor,然后封装成task任务后,提交给对应的业务processor处理线程池来执行(sendMessageExecutor,以发送消息为例,即为上面的 “M2”)。
资料
- rocketmq中的netty使用: 29 从 RocketMQ 学 Netty 网络编程技巧.md
- reactor发展史: 高性能IO之Reactor模式 - 时间朋友 - 博客园
- rocketMQ线程模式: 分布式消息队列 RocketMQ 源码分析 —— RPC 通信(二)
- 单服务器高性能模式:Reactor与Proactor 单服务器高性能模式:Reactor与Proactor