优化步骤
步骤:
1.开启慢查询日志,设置阈值,比如超过5秒钟的就是慢SQL,并将它抓取出来;
2.EXPLAIN+慢SQL分析;
3.SHOW profile,查询SQL在MySQL服务器里面的执行细节和生命周期情况
4.具体优化
explain1
语法explain select * from xxl_job_log l where l.job_id in (select id from xxl_job_info)

访问方法
- 使用全表扫描查询:表的每一行记录都进行一次查询
- 使用索引进行查询
- 针对主键和唯一二级索引
- 针对普通二级索引
- 索引的范围查询
- 直接扫描整个索引
mysql查询语句就是访问方法的类型。同一个语句可能会有不同的路线
type
技巧💡
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL )。最少要到range级别
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part (key_part1,
key_part2,
key_part3)) Engine = InnoDB CHARSET = utf8;system
system:表只有一行记录(等于系统表),是 const 类型的特例,平时不会出现。2
const(唯一索引或者主键索引=某个值)
const:唯一性索引的等值查找,表示通过索引一次就找到了,const 用于比较 primary key 或 unique 索引,因为只要匹配一行数据,所以很快,如将主键置于 where 列表中,mysql 就能将该查询转换为一个常量。可以认为是通过唯一性索引3进行查找。
SELECT * FROM single_table WHERE id = 1438;主键索引

唯一索引
- 先定位查找id,后回表

eq_ref( 和eq类似,主要是用于关联查询join)
eq_ref:唯一性索引的等值关联,唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描。4
ref(普通索引=某个单独值)
ref:非唯一性索引的等值扫描,非唯一性索引扫描,范围匹配某个单独值得所有行。本质上也是一种索引访问,他返回所有匹配某个单独值的行,然而,它可能也会找到多个符合条件的行,多以他应该属于查找和扫描的混合体
SELECT * FROM single_table WHERE key1 = ‘abc’;- 普通二级索引的索引列和常数的等值比较
- 普通索引并不会限制记录的唯一性,所以可能会查询到多条,那么他的查询代价取决于这个值到底有多少个记录,然后进行回表
- 二级索引如果访问的key1 is null都是ref的级别,也就是查询多个
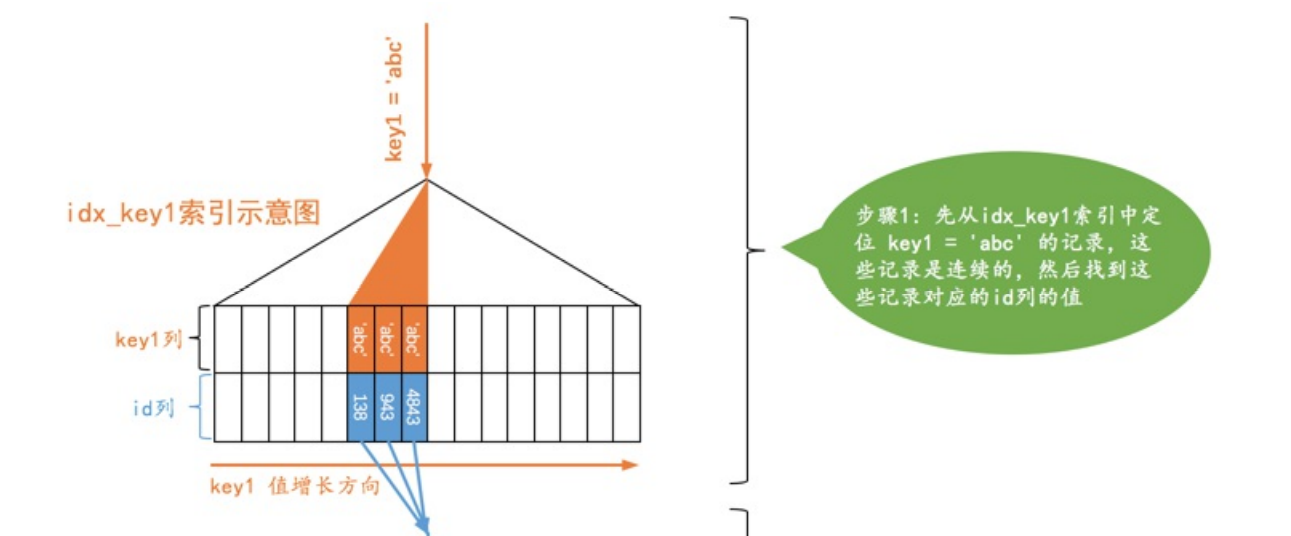
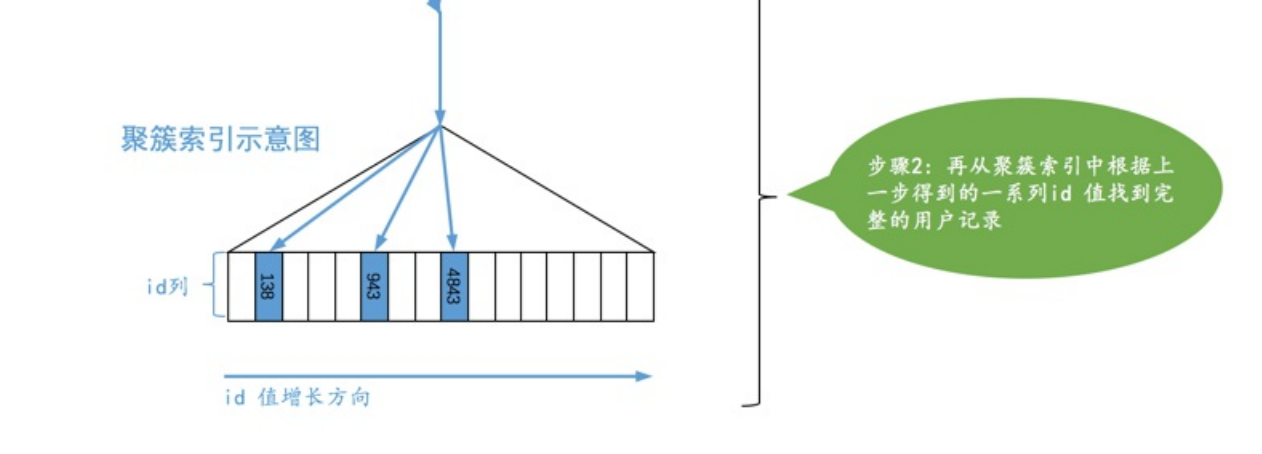
ref_is_null(与ref类型,key1=‘abc’ or key1 is null)
- 这种就是等值列+null的查询,也是扫描好几条数据
SELECT * FROM single_demo WHERE key1 = ‘abc’ OR key1 IS NULL;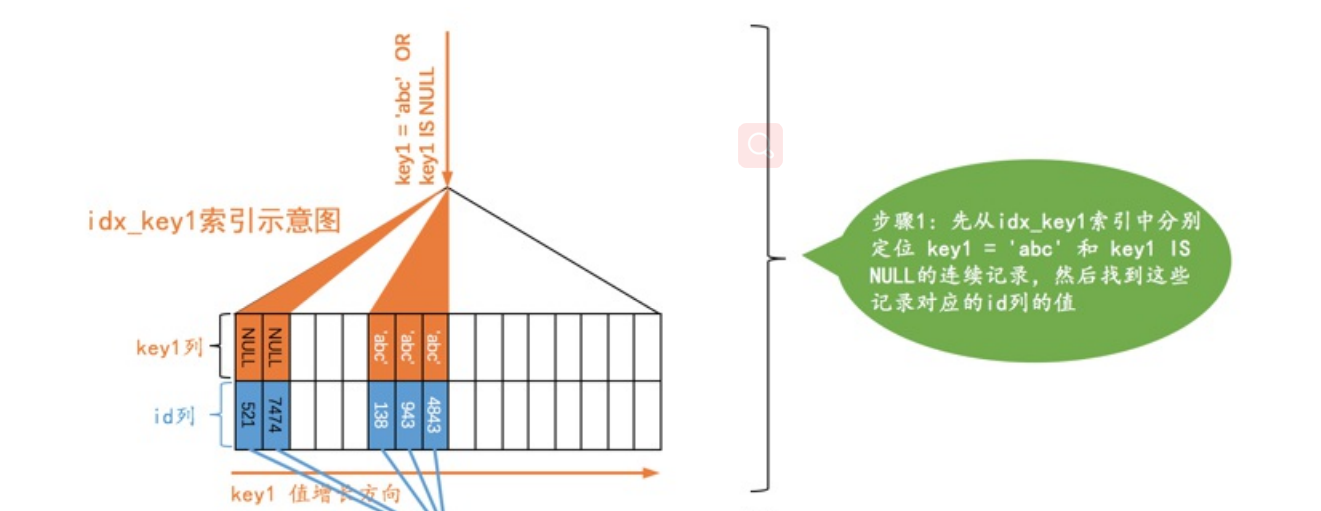

range(范围查询)
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);range:范围查找,不指定唯一索引还是普通索引只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询,这种范围扫描索引比全表扫描要好,因为它只需开始于索引的某一点,而结束于另一点,不用扫描全部索引
index
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = ‘abc’;index:Full Index Scan,index于ALL区别为index类型只遍历索引树。通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
all
ALL:Full Table Scan,将遍历全表找到匹配的行
缺点:
- EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
- EXPLAIN不考虑各种Cache
- EXPLAIN不能显示MySQL在执行查询时所作的优化工作
- 部分统计信息是估算的,并非精确值
- EXPLAIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划
如何推算是否会用到哪些索引?
守则💡
and: where expr1 and expr2. 取交集 。
如where a >100 and a>200 等价于 a>200
or: where expr1 or expr2。取并集。
如where a >100 or a>200 等价于 a>100。这也解释了,为什么很多地方,说只有有or就不走索引。可能是因为 a>100 or b>200。 如果是这种情况,假设a有索引,b没索引。这个等式,等价于 b>200( 扫描行数更多),即等价于不走索引了。exp1 and true —> exp1
exp1 or true —> true
exp1 or false —> exp1
所有条件,都可以走索引
and(交集)
SELECT * FROM single_table WHERE key2 > 100 AND key2 > 200;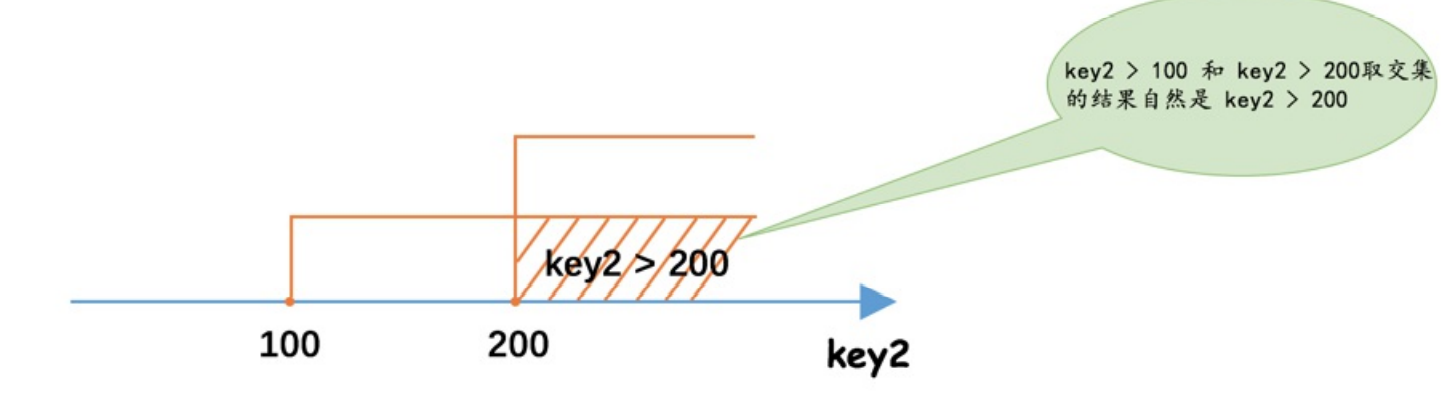
or(并集)
SELECT * FROM single_table WHERE key2 > 100 OR key2 > 200;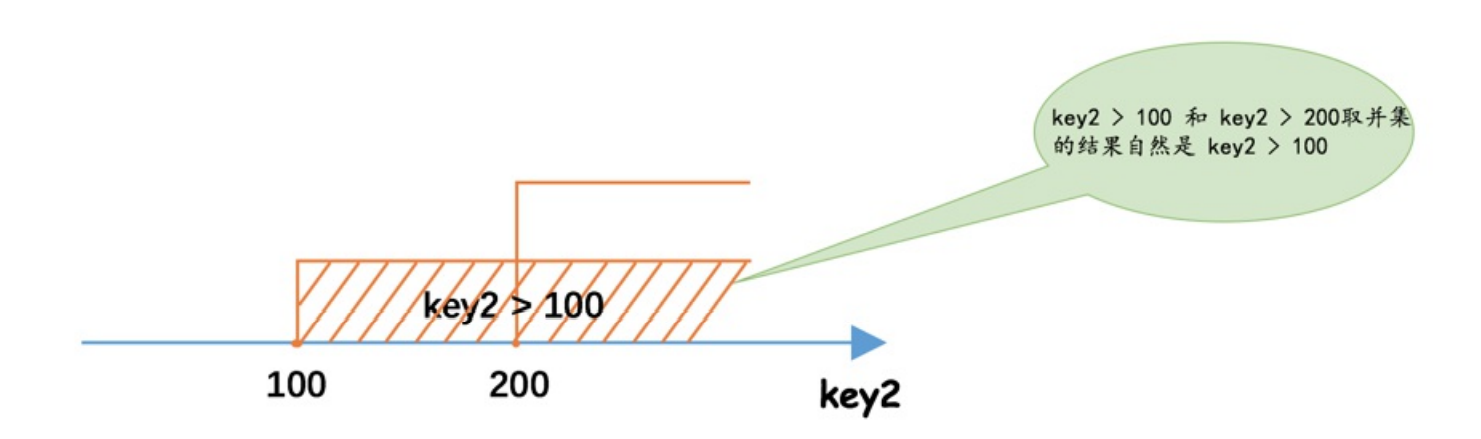
有的查询条件无法使用的情况
SELECT * FROM single_table WHERE key2 > 100 AND common_field = 'abc';索引idx_key2并不包括common_field = ‘abc’;这个条件相当于就是回表的时候才会去使用,也就是在索引上不会过滤这个条件,他也没办法过滤
SELECT * FROM single_table WHERE key2 > 100 AND TRUE;在索引上面这个common_field = ‘abc’;就变成了这个查询,也就是不加以判断。即等价于 key2>100
不走索引
SELECT * FROM single_table WHERE key2 > 100 OR common_field = 'abc';- 等价于 key2>100 or true. —> true
复杂搜索条件找出的范围匹配区间
SELECT * FROM single_table WHERE (key1 > 'xyz' AND key2 = 748 )
OR (key1 < 'abc' AND key1 > 'lmn')
OR (key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc'))结论: 使用 key1索引

猜测,可能使用key1或者key2索引。
- 假设使用key1索引,则 key2和common_field都是全表扫描。则
-- 第一个条件
key1 > 'xyz' AND key2 = 748 --> key1>'xyz' ADN true --> key1>'xyz'
-- 第二个条件
(key1 < 'abc' AND key1 > 'lmn') --> 因为没有交集,所以这个 --> false
-- 第三个条件
(key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc'))
--> key1 LIKE '%suf' AND key1 > 'zzz' AND (true or true)
--> key1 LIKE '%suf' AND key1 > 'zzz'
--> true and key1 > 'zzz'
--> key1 > 'zzz'
-- 规整后
key1>'xyz' or false or key1 > 'zzz'
--> key1>'xyz' or key1 > 'zzz'
--> key1>'xyz'所以,最后的扫描区间为 xyz —> 正无穷
- 假设使用key2作为索引,则key1和common_field都是全表扫描。
-- 第一个条件
(key1 > 'xyz' AND key2 = 748 ) --> true and key2 = 748 -->
-- 第二个条件
(key1 < 'abc' AND key1 > 'lmn') --> true and true --> true
-- 第三个条件
(key1 LIKE '%suf' AND key1 > 'zzz' AND (key2 < 8000 OR common_field = 'abc'))
--> true and true and (key2 < 8000 or true)
--> true and true and true
--> true
-- 规整后
key2 = 748 or true or true --> true这意味着,如果使用key2作为索引,需要进行扫描区间,为负无穷到正无穷。并且还要进行回表获取其他字段信息。得不偿丧。
extra(扩展信息)
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_code` varchar(20) NOT NULL DEFAULT '' COMMENT '唯一索引',
`name` varchar(20) NOT NULL DEFAULT '' COMMENT '名称',
`age` bigint(20) NOT NULL DEFAULT '0' COMMENT '年龄',
`birth_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '生日',
`sex` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '性别',
PRIMARY KEY (`id`),
UNIQUE KEY uniq_user_code(`user_code`),
KEY `idx_age_name` (`name`,`age`),
KEY `idx_birth_date` (`birth_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户';using where (有点类型,是否服务端过滤)
通常来说,意味着全表扫描或者在查找使用索引的情况下,但是还有查询条件不在索引字段当中。
select * from user where sex = 1; -- 不走索引using index
索引覆盖,不进行回表。可以索引的字段信息,就以及满足查询需求了,不需要进行查其他字段信息。索引包含(或者说覆盖)所有需要查询的字段。
select * from user where age = 1; -- extra 为null
select age from user where age = 1; -- extra 为using index。 因为直接使用索引就可以,不用进行查询
select id,user_code from user where user_code = 't'; -- 与是否为使用唯一索引无关using index; using where
索引覆盖和where 的结合。
-- 索引覆盖
select name from user where name = 'xx' and age = 12;
-- using index, using where 这个为什么不是索引下推,很迷惑。我理解是这里不需要回表,可以进行索引覆盖,优先级比索引下推高。
select name from user where name = 'xx' and age > 12;
-- 索引下推(复合索引情况下使用), using index condition
select * from user where name = 'xx' and age > 12;using index condition
索引下推
如name = ‘xx’ and age > 12 为示例,(如果是name = ‘xx’ and age = 12,此时直接使用索引了,也就没有下推的说法了。)
无索引下推: 先定位name的索引,然后回表查询完整记录,在到server层过滤数据。
有索引下推: 先定位name的索引,在索引中,记录判断 age > 12的数据,然后回表查询到完整记录。在server层不用进行过滤了。
-- 索引
select * from user where name = 'xx' and age = 12;
-- 索引覆盖
select name from user where name = 'xx' and age = 12;
-- 索引下推(复合索引情况下使用), using index condition
select * from user where name = 'xx' and age > 12;
-- using index, using where 这个为什么不是索引下推,很迷惑。我理解是这里不需要回表,可以进行索引覆盖,优先级比索引下推高。
select name from user where name = 'xx' and age > 12;
-- 索引下推(索引覆盖不了sex字段) + where , using index condition, using where
select name from user where name = 'xx' and age > 12 and sex = 1;
-- 索引下推(索引覆盖不了sex字段) + where , using index condition, using where
select * from user where name = 'xx' and age > 12 and sex = 1;
总结
结论
在范围查询时,索引覆盖的优先级 > 索引下推。 即能索引覆盖在server层过滤,就尽量使用索引覆盖
技巧💡
等值查询时(name = ‘xxx’ and age = 12)
—索引能够覆盖查询,(select name) 覆盖索引, using index
—索引不能覆盖查询
----索引不需要服务端过滤(select * ) NULL
----索引需要服务端过滤(and sex = 1) using where *
范围查询(name = ‘xxx’ and age > 12)
—索引能够覆盖查询,(select name) using index; using where
—索引不能覆盖查询
----索引不需要服务端过滤(select * ) ** 索引下推, using index condition ;*
---- 索引需要服务端过滤(and sex = 1) 索引下推 + where, using index condition; using where
调优案例
order by limit 导致选错最优索引
大分页
类型不匹配,不走索引
资料
MySQL 三万字精华总结 + 面试100 问,和面试官扯皮绰绰有余(收藏系列) - 掘金
《MySQL是怎么运行的:从根儿上理解MySQL》(8-10)学习总结_从根上理解mysql第八章_月亮的-影子的博客-CSDN博客
Footnotes
-
MySQL 执行计划中Extra(Using where,Using index,Using index condition,Using index,Using where)的浅析 - 潇湘隐者 - 博客园 ↩
-
相当于表中只有一条数据,由于innodb无法准确记录数据库中的表数量,只是预估,所以即使是只有一条数,显示的type也只是const。Why is const rather than system of type in mysql explain? - Stack Overflow ↩
-
唯一性索引,指主键或者唯一索引 ↩
-
eq_ref和const,虽然都是唯一性索引扫描和查找,但是const是在表中使用,而eq_ref主要是用于关联表的时候。即区分关联表和普通表的情况 ↩