::我的理解
JVM调优,都是通过配置JVM参数来进行调优。调优之前,首先要先确定调优的目的。垃圾回收器性能指标
::调优步骤
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 选择回收器组合
- 计算内存需求(经验值 1.5G 16G)
- 选定CPU(越高越好)
- 设定年代大小、升级年龄
- 设定日志参数
- Xloggc:/opt/xxx/logs/xxx-xxx-gc
-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=20M
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCCause - 或者每天产生一个日志文件
- Xloggc:/opt/xxx/logs/xxx-xxx-gc
- 观察日志情况
::调优思路
这个问题在面试中很容易问到,抓住核心回答。
现在都是分代 GC,调优的思路就是尽量让对象在新生代就被回收,防止过多的对象晋升到老年代,减少大对象的分配。
需要平衡分代的大小、垃圾回收的次数和停顿时间。
需要对 GC 进行完整的监控,监控各年代占用大小、YGC 触发频率、Full GC 触发频率,对象分配速率等等。
然后根据实际情况进行调优。
比如进行了莫名其妙的 Full GC,有可能是某个第三方库调了 System.gc。
Full GC 频繁可能是 CMS GC 触发内存阈值过低,导致对象分配不过来。
还有对象年龄晋升的阈值、survivor 过小等等,具体情况还是得具体分析,反正核心是不变的
::调优案例
思路:
- 有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G 的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G 的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了
- 为什么原网站慢? 很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢
- 为什么会更卡顿? 内存越大,FGC时间越长
- 咋办? PS -> PN + CMS 或者 G1
- 系统CPU经常100%,如何调优?(面试高频) CPU100%那么一定有线程在占用系统资源,
- 找出哪个进程cpu高(top)
- 该进程中的哪个线程cpu高(top -Hp)
- 导出该线程的堆栈 (jstack)
- 查找哪个方法(栈帧)消耗时间 (jstack)jstat
- 工作线程占比高 | 垃圾回收线程占比高
- 系统内存飙高,如何查找问题?(面试高频)
- 导出堆内存 (jmap)
- 分析 (jhat jvisualvm mat jprofiler … )
- 如何监控JVM
- jstat jvisualvm jprofiler arthas top…
分类
- 硬件升级系统反而卡顿的问题?
-
内存变大了,原来的垃圾回收器想做一次GC的话,时间反而变得更长了。所以不是说内存变大你的系统一定变得越快,还得选定特定的垃圾回收器才可以。你可以选择ParNew+CMS或者G1或者ZGC
-
- 线程池不当运用产生OOM问题(见内存泄露) 不断的往List里加对象(实在太LOW)
- smile jira问题 加内存 + 更换垃圾回收器 G1。
实际系统不断重启 解决问题 加内存 + 更换垃圾回收器 G1 真正问题在哪儿?不知道 JDK8 开始就可以使用G1了,而且相对来说已经很完善了,到了JDK9的时候,默认就是G1,JDK11或13的时候CMS就已经被干掉了,完成了它的历史使命。 现实当中真的有一部分系统就是在不断的重启,比如游戏服务器,过一段时间就会出现“系统正在维护中,请20分钟后再重试”。比如地下城,以前也是这样的。选择凌晨的时候,集群中逐台重启,实在不行就来一次大重启。比如12306,每天晚上11点~第二天7点,是不能买票的,在维护
- 直接内存溢出问题(少见)
《深入理解Java虚拟机》P59,使用Unsafe分配直接内存,或者使用NIO的问题。
- 栈溢出问题
-Xss设定太小
- 重写finalize引发频繁GC
小米云,HBase同步系统,系统通过nginx访问超时报警,最后排查,C++程序员重写finalize引发频繁GC问题 为什么C++程序员会重写finalize?(new delete) finalize耗时比较长(200ms)
- 如果有一个系统,内存一直消耗不超过10%,但是观察GC日志,发现FGC总是频繁产生,会是什么引起的?
System.gc() (这个比较Low)
- Distuptor有个可以设置链的长度,如果过大,然后对象大,消费完不主动释放,会溢出.
::内存泄露示例,jstack 栈
package com.mashibing.jvm.gc;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 从数据库中读取信用数据,套用模型,并把结果进行记录和传输
*/
public class T15_FullGC_Problem01 {
private static class CardInfo {
BigDecimal price = new BigDecimal(0.0);
String name = "张三";
int age = 5;
Date birthdate = new Date();
public void m() {}
}
private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
public static void main(String[] args) throws Exception {
executor.setMaximumPoolSize(50);
for (;;){
modelFit();
Thread.sleep(100);
}
}
private static void modelFit(){
List<CardInfo> taskList = getAllCardInfo();
taskList.forEach(info -> {
// do something
executor.scheduleWithFixedDelay(() -> {
//do sth with info
info.m();
}, 2, 3, TimeUnit.SECONDS);
});
}
private static List<CardInfo> getAllCardInfo(){
List<CardInfo> taskList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
CardInfo ci = new CardInfo();
taskList.add(ci);
}
return taskList;
}
}- 代码
2.java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01 - 一般是运维团队首先受到报警信息(CPU Memory)
- top命令观察到问题:内存不断增长 CPU占用率居高不下
- top -Hp 观察进程中的线程,哪个线程CPU和内存占比高
- jps定位具体java进程 jstack 定位线程状况,重点关注:WAITING BLOCKED eg. waiting on <0x0000000088ca3310> (a java.lang.Object) 假如有一个进程中100个线程,很多线程都在waiting on xx ,一定要找到是哪个线程持有这把锁 怎么找?搜索jstack dump的信息,找xx ,看哪个线程持有这把锁RUNNABLE 作业:1:写一个死锁程序,用jstack观察 2 :写一个程序,一个线程持有锁不释放,其他线程等待
- 为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称 怎么样自定义线程池里的线程名称?(自定义ThreadFactory)
::堆 jmap
jmap - histo 4655 | head -20,查找有多少对象产生
::常见问题
1.生产环境中,倾向于将最大堆内存和最小堆内存设置为:(为什么?)
总结:避免每次垃圾回收完成后JVM重新分配内存。
A: 相同 B:不同
A,好处是:
1) 避免JVM在运行过程中向操作系统申请内存
2)延后启动后首次GC的发生时机
3)减少启动初期的GC次数
-
什么是响应时间优先?
注重的是垃圾回收时STW的时间最短。 -
什么是吞吐量优先?
吞吐量是指应用程序线程用时占程序总用时的比例,也就是说尽量躲让用户程序去执行。 -
ParNew和PS的区别是什么?
都是年轻代多线程收集器。
ParNew 回收器是通过控制 垃圾回收 的 线程数 来进行参数调整,而 Parallel Scavenge 回收器更关心的是程序运行的吞吐量。即一段时间内,用户代码 运行时间占 总运行时间 的百分比。 -
ParNew和ParallelOld的区别是什么?(年代不同,算法不同) 、
前者是年轻代收集器,后者是老年代收集器,然后解释两者。 -
长时间计算的场景应该选择:吞吐量优先的收集器和策略。
-
大规模电商网站应该选择:停顿时间少(即响应时间快)的收集器和策略。
-
JDK1.7 1.8 1.9的默认垃圾回收器是什么?如何查看?
jdk1.7 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代);
jdk1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代);
jdk1.9 默认垃圾收集器G1。
java -XX:+PrintCommandLineFlags -version命令可以查看使用的垃圾回收器。 -
所谓调优,到底是在调什么?
本人认为,是根据业务需要,在吞吐量和响应时间之间做出选择。 -
如果采用PS + ParrallelOld组合,怎么做才能让系统基本不产生FGC
应该和下个问题的答案是有相通之处的。 -
如果采用ParNew + CMS组合,怎样做才能够让系统基本不产生FGC
1)加大JVM内存
2)加大Young(年轻代)的比例
3)提高Y-O(最大值是15)的年龄
4)提高S(survivor)区比例
5)避免代码内存泄漏 -
如果G1产生FGC,你应该做什么?
1)扩内存
2)提高CPU性能(回收的快,业务逻辑产生对象的速度固定,垃圾回收越快,内存空间越大)
3)降低MixedGC触发的阈值,让MixedGC提早发生(默认是45%)。具体的参数是:
-XX:InitiatingHeapOccupancyPercent=45- 问:生产环境中能够随随便便的dump吗?
小堆影响不大,大堆会有服务暂停或卡顿(加live可以缓解),dump前会有FGC - 问:常见的OOM问题有哪些?
栈 堆 MethodArea 直接内 - 如果JVM进程静悄悄退出怎么办?
- JVM自身OOM导致
- heap dump on oom,这种最容易解决
- JVM自身故障
- XX:ErrorFile=/var/log/hs_err_pid pid.log 超级复杂的文件 包括:crash线程信息 safepoint信息 锁信息 native code cache , 编译事件, gc相关记录 jvm内存映射 等等
- 被Linux OOM killer杀死
- 日志位于/var/log/messages
- egrep -i ‘killed process’ /var/log/messages
- 硬件或内核问题
- dmesg | grep java
- JVM自身OOM导致
- 如何排查直接内存?
- NMT打开 — -XX:NativeMemoryTracking=detail
- perf工具
- gperftools
- 有哪些常用的日志分析工具?
- gceasy
- CPU暴增如何排查?
- top -Hp jstack
- arthas - dashboard thread thread XXXX
- 两种情况:1:业务线程 2:GC线程 - GC日志
- 死锁如何排查?
- jstack 观察线程情况
- arthas - thread -b
::优秀调优经历blog
YGC时间变长 —> 长生命周期的对象越来越多,导致标注和复制过程的耗时增加
YGC 时间变长
- 猜测, 长生命周期的对象越来越多,导致标注和复制过程的耗时增加
- 局部变量来说,在每次YGC后就能够马上被回收了。所以不会是局部变量
- 猜测,全局变量或者类静态变量上。这些变量不会马上被回收。也不会马上到老年代
- jmap,查看有哪些大对象,进行猜测。后发现是静态变量一直添加,未去重
- 其它思路:
- 对存活对象标注时间过长:比如重载了Object类的Finalize方法,导致标注Final Reference耗时过长;或者String.intern方法使用不当,导致YGC扫描StringTable时间过长。
- 长周期对象积累过多:比如本地缓存使用不当,积累了太多存活对象;或者锁竞争严重导致线程阻塞,局部变量的生命周期变长。
YGC问题排查,又让我涨姿势了! | HeapDump性能社区
元空间内存泄露,直接内存溢出
内存上涨,宕机
- 内存使用,超过了堆内存上限。猜测是直接内存溢出
- 使用jcmd来查看堆外内存。需要jvm参数设置支持跟踪堆外内存
- 启动参数新增 -verbose:class,发现fastjson有个类频繁创建
- fastjson序列化,用使用asm创建动态代理类,导致动态代理类激增
每个SerializeConfig实例若序列化相同的类, 都会找到之前生成的该类的代理类, 来进行序列化. 们的服务在每次接口被调用时, 都实例化一个ParseConfig对象来配置Fastjson反序列的设置, 而未禁用ASM代理的情况下, 由于每次调用ParseConfig都是一个新的实例, 因此永远也检查不到已经创建的代理类, 所以Fastjson便不断的创建新的代理类, 并加载到metaspace中, 最终导致metaspace不断扩张, 将机器的内存耗尽
/**
* 返回Json字符串.驼峰转_
* @param bean 实体类.
*/
public static String buildData(Object bean) {
try {
SerializeConfig CONFIG = new SerializeConfig();
CONFIG.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
return jsonString = JSON.toJSONString(bean, CONFIG);
} catch (Exception e) {
return null;
}
}log.info 大对象使用
线上服务的FGC问题排查,看这篇就够了! | HeapDump性能社区
一次由JVM参数、中间件配置引起的FGC性能调优 | HeapDump性能社区
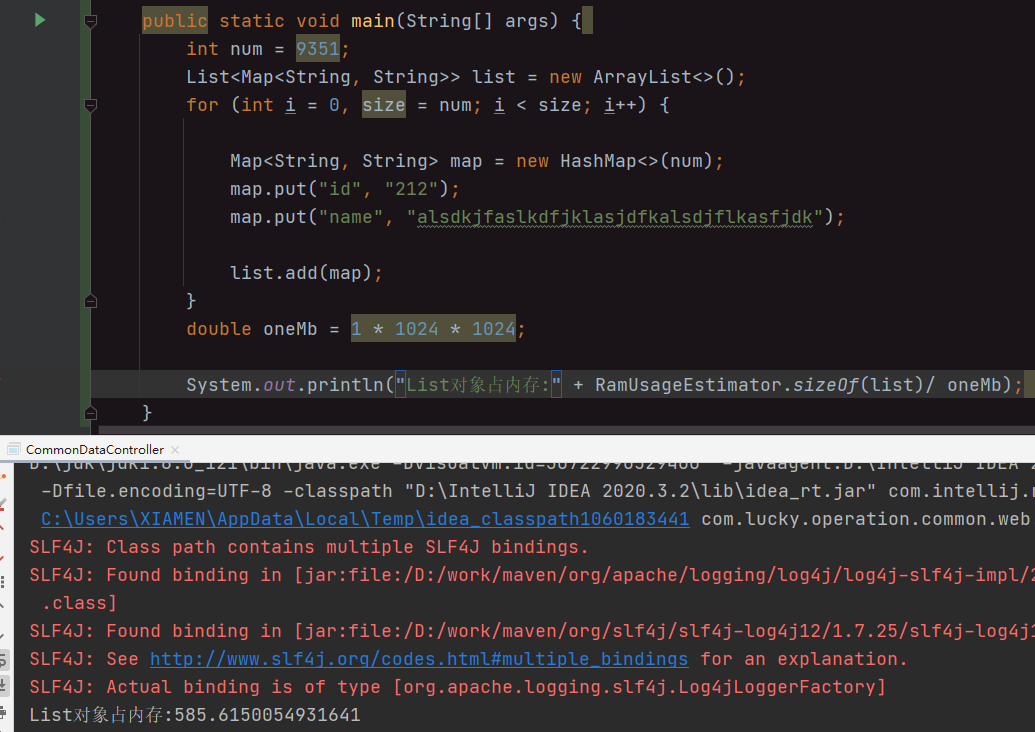
HashMap错误设置size,导致List占用过大
List占用了500MB,正常使用仅2MB
wiki:88648630
几百万数据放入内存不会把系统撑爆吗? - Mr.墨斗的博客 | MoDou Blog
:: 大厂真题
排查方向
YGC是什么时候触发的?
大多数情况下,对象直接在年轻代中的Eden区进行分配,如果Eden区域没有足够的空间,那么就会触发YGC(Minor GC),YGC处理的区域只有新生代。因为大部分对象在短时间内都是可收回掉的,因此YGC后只有极少数的对象能存活下来,而被移动到S0区(采用的是复制算法)。
当触发下一次YGC时,会将Eden区和S0区的存活对象移动到S1区,同时清空Eden区和S0区。当再次触发YGC时,这时候处理的区域就变成了Eden区和S1区(即S0和S1进行角色交换)。每经过一次YGC,存活对象的年龄就会加1。
FGC又是什么时候触发的?
下面4种情况,对象会进入到老年代中:
- YGC时,To Survivor区不足以存放存活的对象,对象会直接进入到老年代。
- 经过多次YGC后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。
- 动态年龄判定规则,To Survivor区中相同年龄的对象,如果其大小之和占到了 To Survivor区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达到默认的分代年龄。
- 大对象:由-XX:PretenureSizeThreshold启动参数控制,若对象大小大于此值,就会绕过新生代, 直接在老年代中分配。
当晋升到老年代的对象大于了老年代的剩余空间时,就会触发FGC(Major GC),FGC处理的区域同时包括新生代和老年代。除此之外,还有以下4种情况也会触发FGC: - 老年代的内存使用率达到了一定阈值(可通过参数调整),直接触发FGC。
- 空间分配担保:在YGC之前,会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果小于,说明YGC是不安全的,则会查看参数 HandlePromotionFailure 是否被设置成了允许担保失败,如果不允许则直接触发Full GC;如果允许,那么会进一步检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果小于也会触发 Full GC。
- Metaspace(元空间)在空间不足时会进行扩容,当扩容到了-XX:MetaspaceSize 参数的指定值时,也会触发FGC。
- System.gc() 或者Runtime.gc() 被显式调用时,触发FGC。
在什么情况下,GC会对程序产生影响?
不管YGC还是FGC,都会造成一定程度的程序卡顿(即Stop The World问题:GC线程开始工作,其他工作线程被挂起),即使采用ParNew、CMS或者G1这些更先进的垃圾回收算法,也只是在减少卡顿时间,而并不能完全消除卡顿。
-
FGC过于频繁:FGC通常是比较慢的,少则几百毫秒,多则几秒,正常情况FGC每隔几个小时甚至几天才执行一次,对系统的影响还能接受。但是,一旦出现FGC频繁(比如几十分钟就会执行一次),这种肯定是存在问题的,它会导致工作线程频繁被停止,让系统看起来一直有卡顿现象,也会使得程序的整体性能变差。
-
YGC耗时过长:一般来说,YGC的总耗时在几十或者上百毫秒是比较正常的,虽然会引起系统卡顿几毫秒或者几十毫秒,这种情况几乎对用户无感知,对程序的影响可以忽略不计。但是如果YGC耗时达到了1秒甚至几秒(都快赶上FGC的耗时了),那卡顿时间就会增大,加上YGC本身比较频繁,就会导致比较多的服务超时问题。
-
FGC耗时过长:FGC耗时增加,卡顿时间也会随之增加,尤其对于高并发服务,可能导致FGC期间比较多的超时问题,可用性降低,这种也需要关注。
-
YGC过于频繁:即使YGC不会引起服务超时,但是YGC过于频繁也会降低服务的整体性能,对于高并发服务也是需要关注的。
其中,「FGC过于频繁」和「YGC耗时过长」,这两种情况属于比较典型的GC问题,大概率会对程序的服务质量产生影响。剩余两种情况的严重程度低一些,但是对于高并发或者高可用的程序也需要关注。
排查FGC问题的实践指南
通过上面的案例分析以及理论介绍,再总结下FGC问题的排查思路,作为一份实践指南供大家参考。
清楚从程序角度,有哪些原因导致FGC?
- 大对象:系统一次性加载了过多数据到内存中(比如SQL查询未做分页),导致大对象进入了老年代。
- 内存泄漏:频繁创建了大量对象,但是无法被回收(比如IO对象使用完后未调用close方法释放资源),先引发FGC,最后导致OOM.
- 程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,最后引发FGC. (即本文中的案例)
- 程序BUG导致动态生成了很多新类,使得 Metaspace 不断被占用,先引发FGC,最后导致OOM.
- 代码中显式调用了gc方法,包括自己的代码甚至框架中的代码。
- JVM参数设置问题:包括总内存大小、新生代和老年代的大小、Eden区和S区的大小、元空间大小、垃圾回收算法等等。
清楚排查问题时能使用哪些工具
公司的监控系统:大部分公司都会有,可全方位监控JVM的各项指标。
JDK的自带工具,包括jmap、jstat等常用命令:
查看堆内存各区域的使用率以及GC情况
- jstat -gcutil -h20 pid 1000
查看堆内存中的存活对象,并按空间排序
- jmap -histo pid | head -n20
dump堆内存文件
- jmap -dump:format=b,file=heap pid
可视化的堆内存分析工具:JVisualVM、MAT等
排查指南
- 查看监控,以了解出现问题的时间点以及当前FGC的频率(可对比正常情况看频率是否正常)
- 了解该时间点之前有没有程序上线、基础组件升级等情况。
- 了解JVM的参数设置,包括:堆空间各个区域的大小设置,新生代和老年代分别采用了哪些垃圾收集器,然后分析JVM参数设置是否合理。
- 再对步骤1中列出的可能原因做排除法,其中元空间被打满、内存泄漏、代码显式调用gc方法比较容易排查。
- 针对大对象或者长生命周期对象导致的FGC,可通过 jmap -histo 命令并结合dump堆内存文件作进一步分析,需要先定位到可疑对象。
- 通过可疑对象定位到具体代码再次分析,这时候要结合GC原理和JVM参数设置,弄清楚可疑对象是否满足了进入到老年代的条件才能下结论。