技巧💡
基本原理就是“二分区间,区间编码”。当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
geohash的bit位数,可以标识它的精度。即区块的大小精度
首先,我们来看下经度和纬度的单独编码过程。
对于一个地理位置信息来说,它的经度范围是[-180,180]。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N 可以自定义。
在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](我称之为左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。
然后,我们再对经度值所属的分区再做一次二分区,同时再次查看经度值落在了二分区后的左分区还是右分区,按照刚才的规则再做 1 位编码。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
举个例子,假设我们要编码的经度值是 116.37,我们用 5 位编码值(也就是 N=5,做 5 次分区)。
我们先做第一次二分区操作,把经度区间[-180,180]分成了左分区[-180,0) 和右分区[0,180],此时,经度值 116.37 是属于右分区[0,180],所以,我们用 1 表示第一次二分区后的编码值。
接下来,我们做第二次二分区:把经度值 116.37 所属的[0,180]区间,分成[0,90) 和[90, 180]。此时,经度值 116.37 还是属于右分区[90,180],所以,第二次分区后的编码值仍然为 1。等到第三次对[90,180]进行二分区,经度值 116.37 落在了分区后的左分区[90, 135) 中,所以,第三次分区后的编码值就是 0。
按照这种方法,做完 5 次分区后,我们把经度值 116.37 定位在[112.5, 123.75]这个区间,并且得到了经度值的 5 位编码值,即 11010。这个编码过程如下表所示:
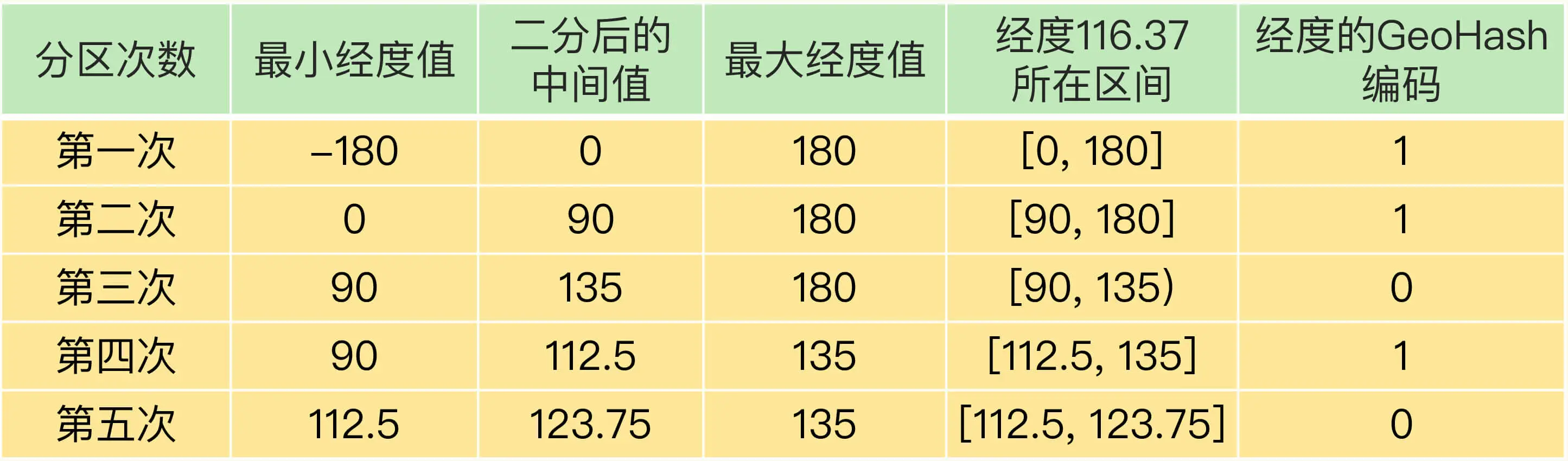
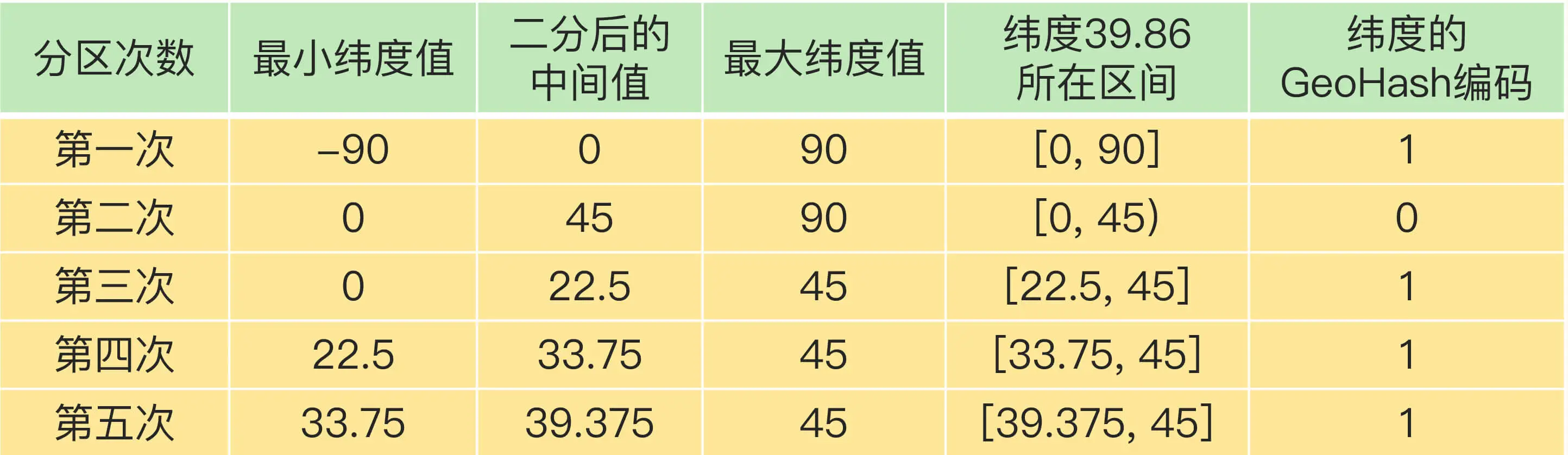
对纬度的编码方式,和对经度的一样,只是纬度的范围是[-90,90],下面这张表显示了对纬度值 39.86 的编码过程。
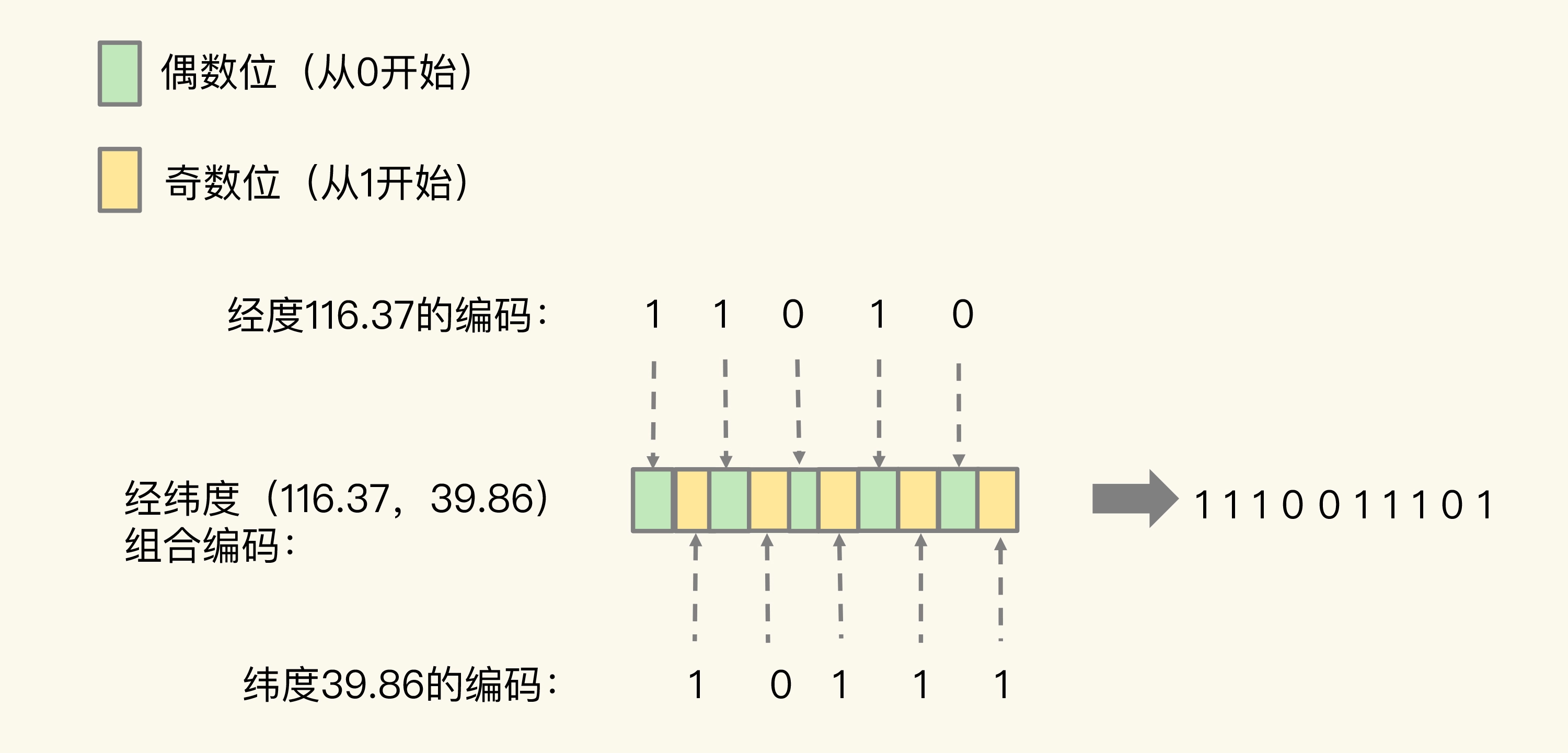
当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始。
我们刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,组合之后,第 0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3 位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,如下图所示:
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
当然,使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。
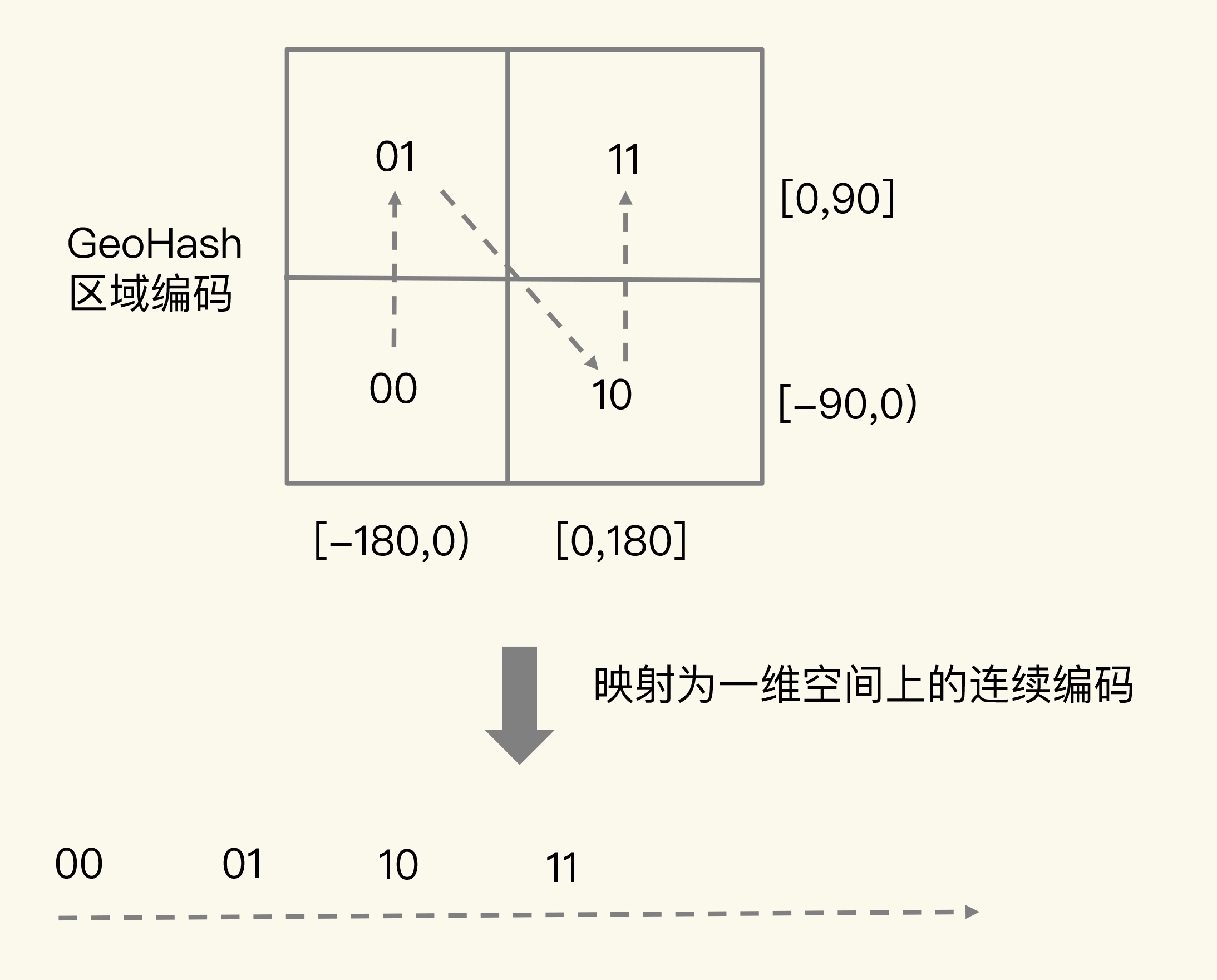
举个例子。我们把经度区间[-180,180]做一次二分区,把纬度区间[-90,90]做一次二分区,就会得到 4 个分区。我们来看下它们的经度和纬度范围以及对应的 GeoHash 组合编码。
- 分区一:[-180,0) 和[-90,0),编码 00;
- 分区二:[-180,0) 和[0,90],编码 01;
- 分区三:[0,180]和[-90,0),编码 10;
- 分区四:[0,180]和[0,90],编码 11。
这 4 个分区对应了 4 个方格,每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。我们把所有方格的编码值映射到一维空间时,相邻方格的 GeoHash 编码值基本也是接近的,如下图所示:
所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现 LBS 应用“搜索附近的人或物”的功能了。
不过,我要提醒你一句,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。例如,我们用 4 位来做 GeoHash 编码,把经度区间[-180,180]和纬度区间[-90,90]各分成了 4 个分区,一共 16 个分区,对应了 16 个方格。编码值为 0111 和 1000 的两个方格就离得比较远,如下图所示:
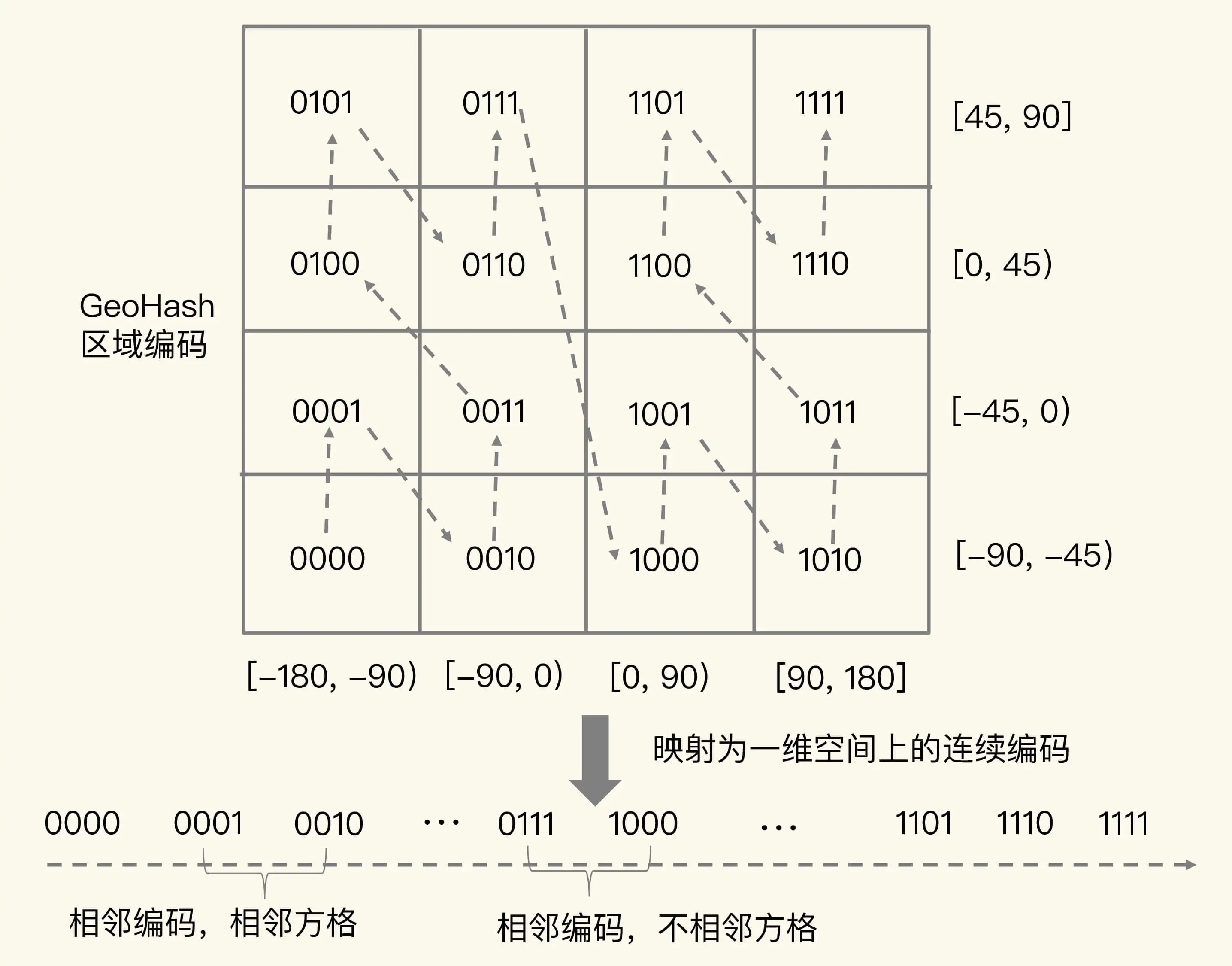
所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格。