缓存的作用
缓存的作用💡
引用缓存,是为了提供查询性能。在redis和数据库中,就会存在不一致的场景。
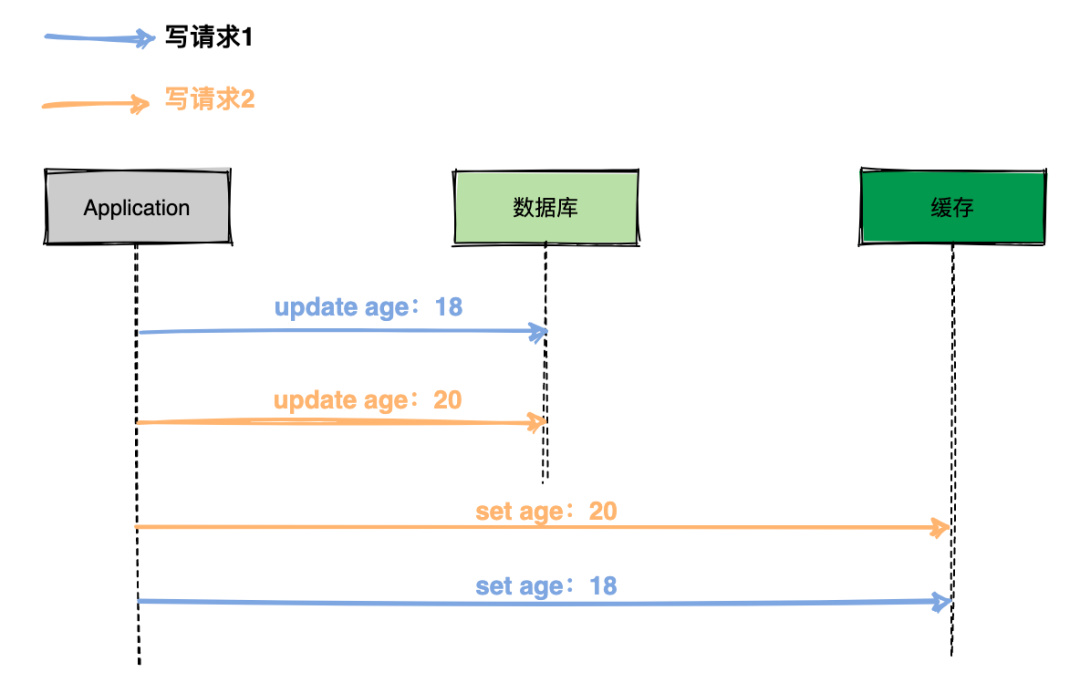
- 由于并发问题,2个线程可能对同一条数据进行并发修改。即 写缓存的操作不可行。
演进过程
首先,先不考虑执行失败的场景。
-
由于并发问题,2个线程可能对同一条数据进行并发修改。即 写缓存的操作不可行。只能改用删除缓存的方式。即AB线程的更新缓存顺序不一定一致。
-
删除缓存
-
先删除缓存,在更新数据库
当发生「读+写」并发时,还是存在数据不一致的情况。
-
先更新数据库,在删除缓存(基本能认为数据一致)但是有个主从同步问题。
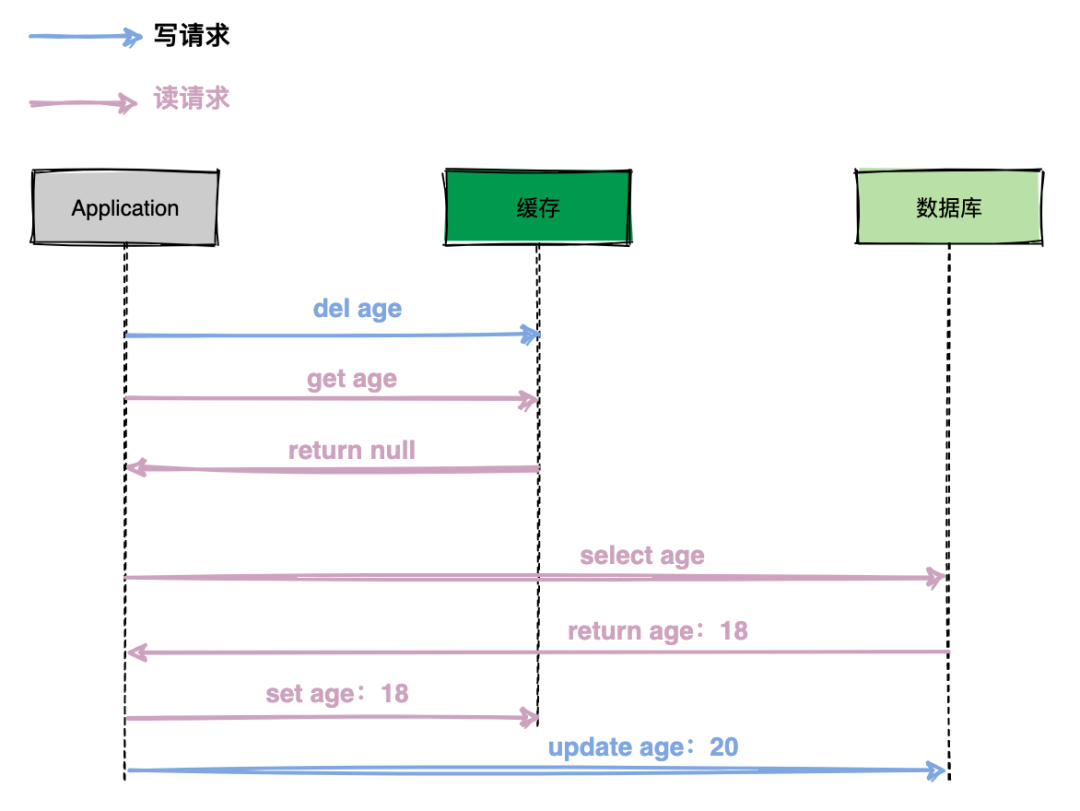
依旧是 2 个线程并发「读写」数据:

- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
这种情况「理论」来说是可能发生的,但实际真的有可能发生吗?
其实概率「很低」,这是因为它必须满足 3 个条件: - 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间短(步骤 2 和 5)
-
-
先更新数据库,延迟删除缓存。解决同步问题。 即在线程 A 删除缓存、更新完数据库之后,先「休眠一会」,再「删除」一次缓存
考虑执行失败,方案就是重试,—> 异步重试(消息队列) —> 订阅数据库变更日志,再操作缓存。
总结: 延迟双删, + 消息队列重试,或者cannal
「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率。