应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。
操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问。
MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
技巧💡
很多性能问题,可以增加缓存来处理。比如处理器,增加一级、二级缓存加快访问速度。✨分布式多级缓存.
可能缓存和数据库一致性问题。
常见问题
缓存穿透(预设空值,如”NULL”, Bloom过滤器 )
查询缓存中不存在的数据时,每次都要查询数据库。
缓存击穿(热点key失效)
假设在缓存失效的同时,出现多个客户端并发请求获取同一个 key 的情况,此时因为 key 已经过期了,所有请求在缓存数据库中查询 key 不命中,那么所有请求就会到数据库中去查询,然后当查询到数据之后,所有请求再重复将查询到的数据更新到缓存中。
同时失效,都去查数据库了、
分布式锁
使用setnx,保证在同一时间只能有一个请求来查询数据库并更新缓存系统,其他请求只能等待重新发起查询,从而解决缓存并发的问题。
异步加载
- 异步加载:由于缓存击穿是热点数据才会出现的问题,可以对这部分热点数据采取到期自动刷新的策略,而不是到期自动淘汰。淘汰其实也是为了数据的时效性,所以采用自动刷新也可以。
缓存雪崩(多key同时失效,增加随机过期时间、多级缓存)
多key💡
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩
很多缓存同时失效,导致都去查数据库了。
缓存和数据库的一致性、缓存容量限制,以及每次存放到缓存的数据大todo
缓存和数据库一致性进行解决。通过延长双删来解决。
缓存实战案例
热点数据动态缓存
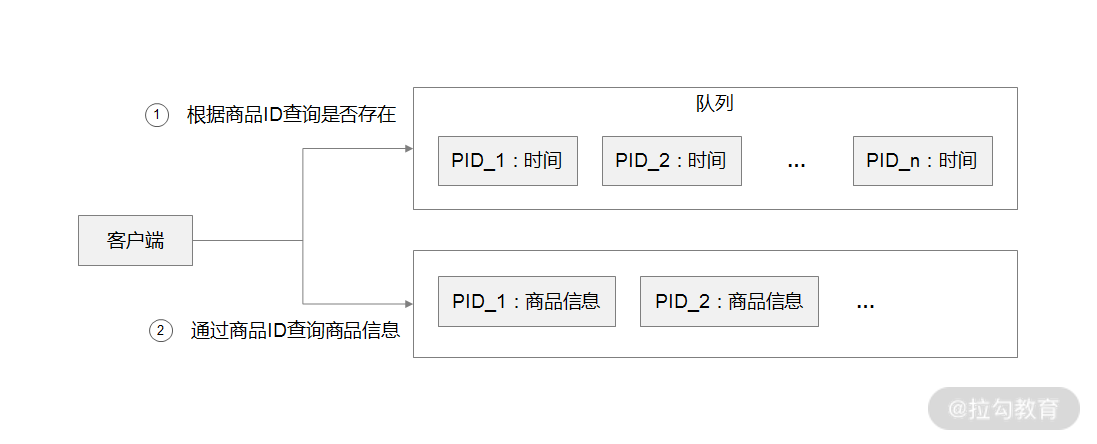
- 先通过缓存系统做一个排序队列(比如存放 1000 个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前。
- 同时系统会定期过滤掉队列中排名最后的 200 个商品,然后再从数据库中随机读取出 200 个商品加入队列中。
- 这样当请求每次到达的时候,会先从队列中获取商品 ID,如果命中,就根据 ID 再从另一个缓存数据结构中读取实际的商品信息,并返回。
- 在 Redis 中可以用 zadd 方法和 zrange 方法来完成排序队列和获取 200 个商品的操作。
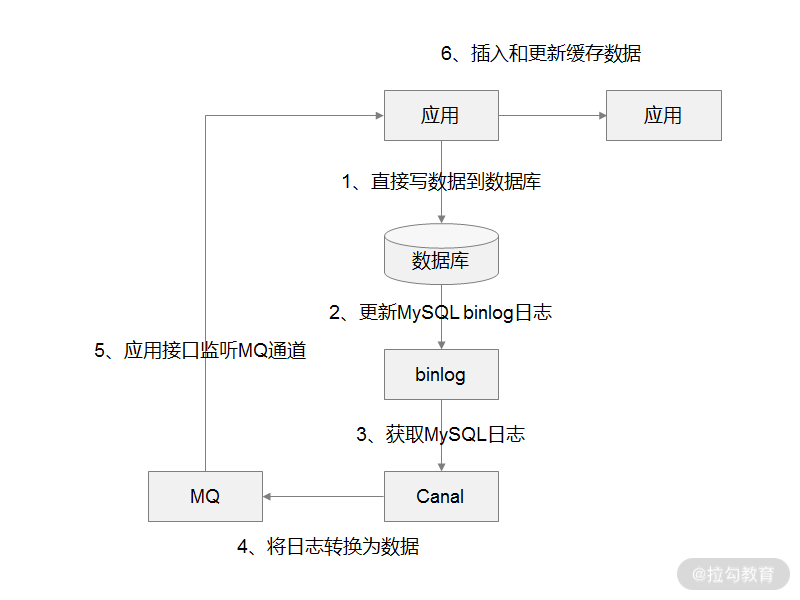
缓存操作与业务分离(MySQL Binlog + Canal + MQ)
资料
- 14 | 缓存策略:面试中如何回答缓存穿透、雪崩等问题?.html