[TOC]
上锁与排除
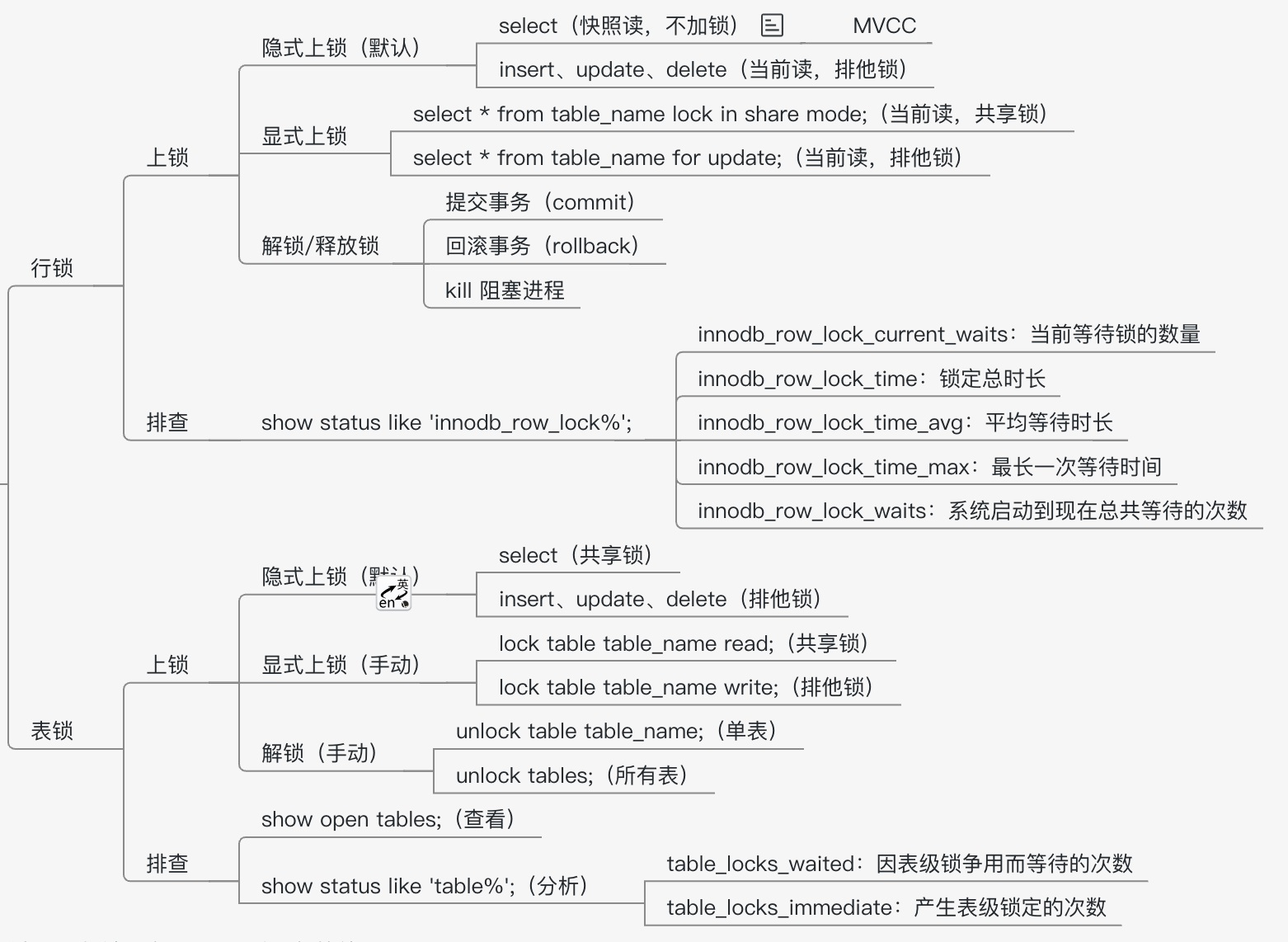
上锁模式 💡
- 快照读,不加锁。如普通的select
- 隐式加锁, inser,update,delete 加 X锁。排他锁
- 显示上锁。 select lock in share mode 加S锁。其它都是排他锁
- 显示上锁。 select * from table_name for update;(当前读,排他锁)
- 表级别
lock table table_name read;(共享锁)
lock table table_name write;(排他锁)
加锁过程
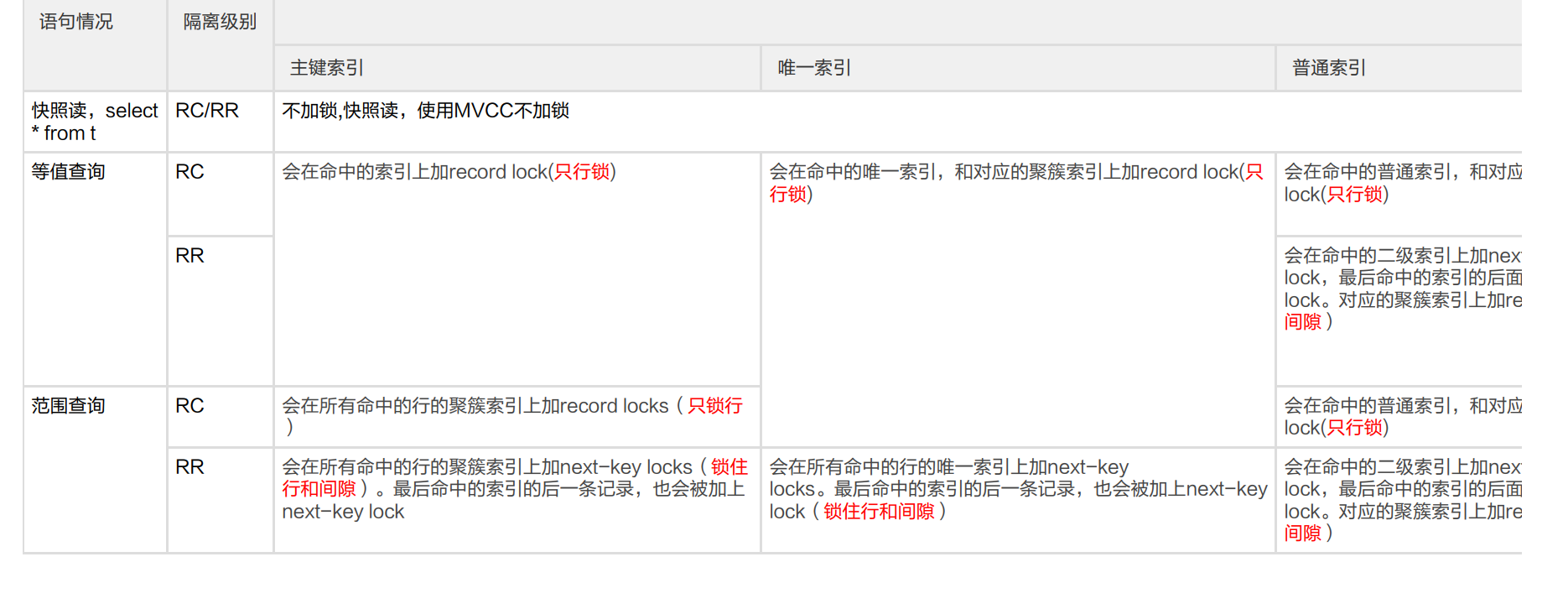
- 针对快照读,不管RC还是RR都不加锁。通过MVCC来解决
- RC 针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。
- RR 针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
原则
- 加锁的基本单位是next-key lock。希望你还记得,next-key lock是前开后闭区间
- 找过程中访问到的对象才会加锁。
- 索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁
- 从第一个满足等值条件的索引记录开始向右遍历到第一个不满足等值条件记录,并将第一个不满足等值条件记录上的next-key lock 退化为间隙锁。
RC隔离级别下的加锁
技巧💡
针对当前读,RC隔离级别,指挥对索引命中的对象加锁(记录锁)。简单理解,无论等值查询,还是范围查询,用到的索引才对这个索引加锁,如果需要回表,则也会对聚簇索引加锁。
RC隔离级别下,id为主键 delete from t where id = 10;
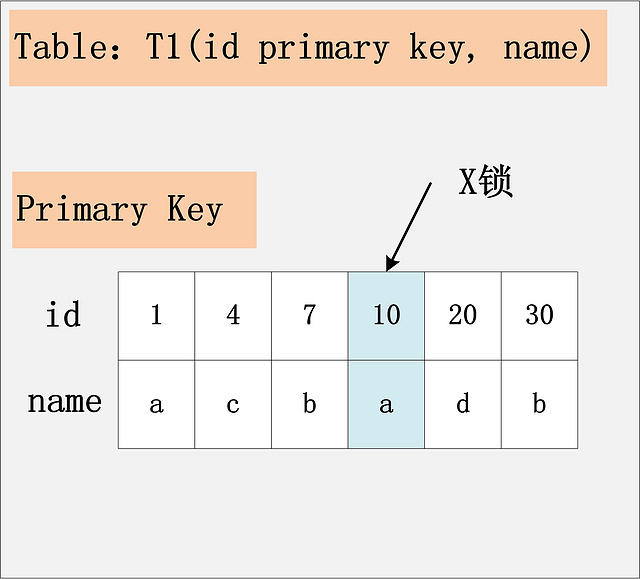
只需要将主键上,id = 10的记录加上X锁即可
RC隔离级别下,id为唯一索引
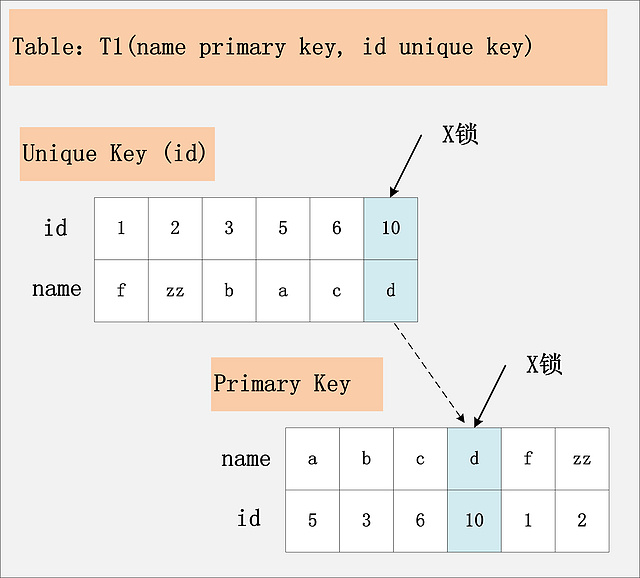
若id列上有唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
RC隔离级别下,id为普通索引
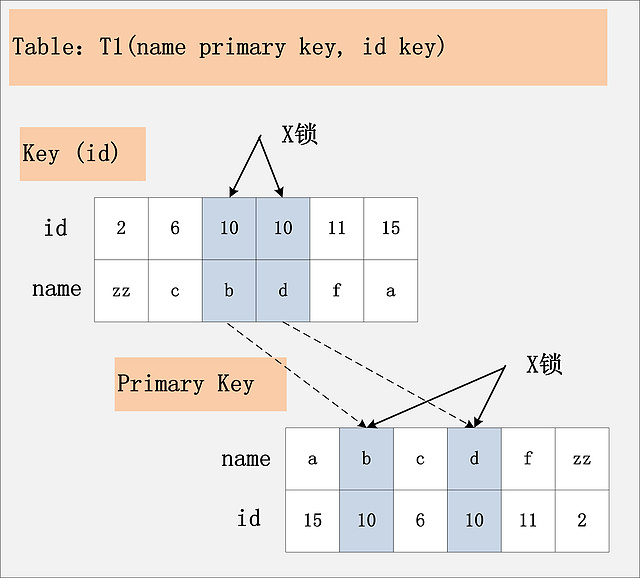
若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁
RC隔离级别下,id没有索引
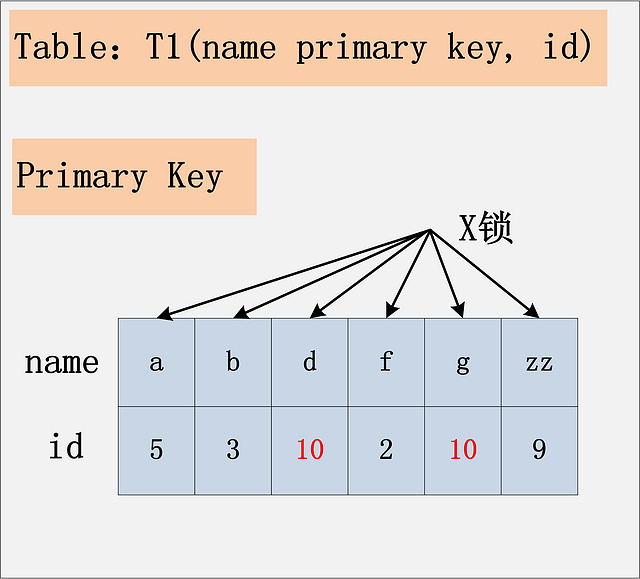
若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束
RR隔离级别下加锁
技巧💡
RR 针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
RR隔离级别下和RC隔离级别,除了可重复读外,在innodb中,还解决了幻读。也就是通过间隙锁方式来处理,避免被插入、修改。
这里可以想到,有优化点,
- 如果索引能保证唯一性(聚簇索引或者唯一索引)。一个等值查询,最多只能返回一条记录,而且新的相同取值的记录,一定不会在新插入进来。可以避免使用GAP锁。
- 从第一个满足等值条件的索引记录开始向右遍历到第一个不满足等值条件记录,并将第一个不满足等值条件记录上的next-key lock 退化为间隙锁。
RR隔离级别下,id为主键/唯一索引
等值查询,会根据优化1,会退化成行锁,加X锁。与RC下一样。
RR隔离级别下,id为普通索引
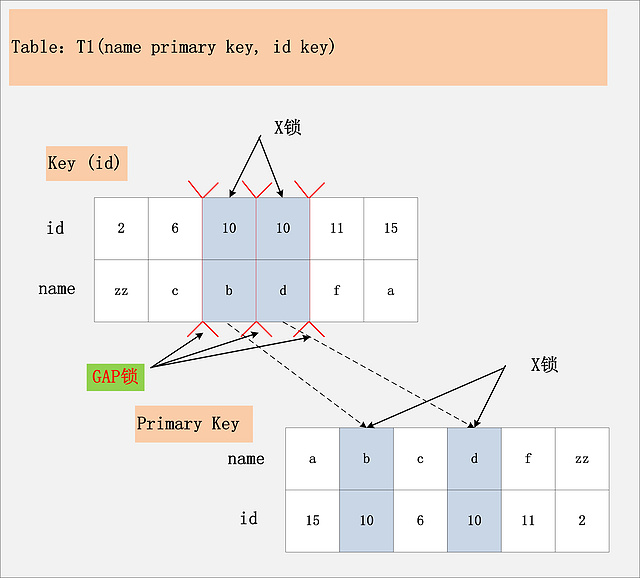
Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
RR隔离级别下,id无索引
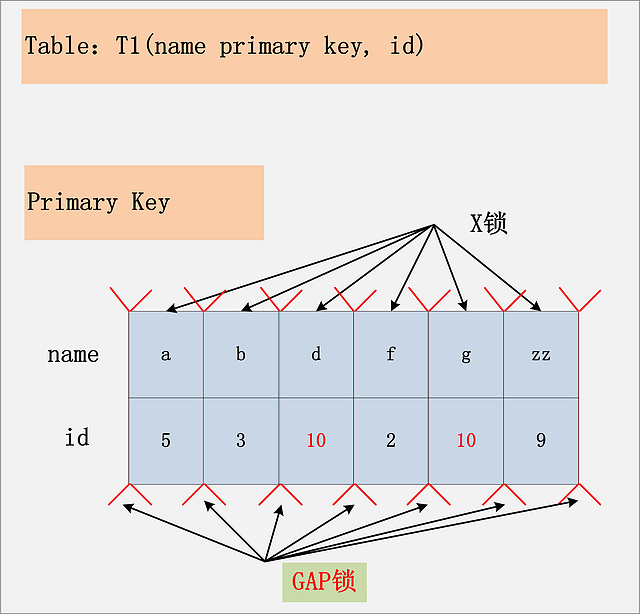
首先,聚簇索引上的所有记录,都被加上了X锁。其次,聚簇索引每条记录间的间隙(GAP),也同时被加上了GAP锁。这个示例表,只有6条记录,一共需要6个记录锁,7个GAP锁。
在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。当然,也可以通过触发semi-consistent read,来缓解加锁开销与并发影响,但是semi-consistent read本身也会带来其他问题,不建议使用.
综合案例-复杂SQL加锁过程
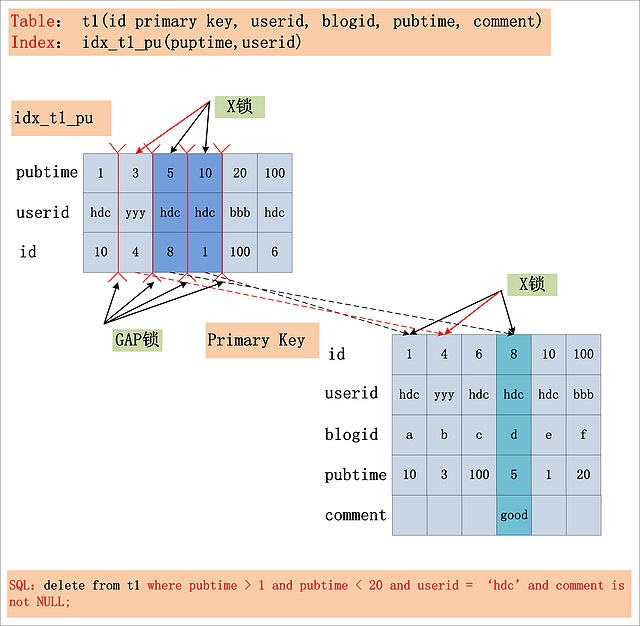
技巧💡
在Repeatable Read隔离级别下,针对一个复杂的SQL,首先需要提取其where条件。Index Key确定的范围,需要加上GAP锁;Index Filter过滤条件,视MySQL版本是否支持ICP,若支持ICP,则不满足Index Filter的记录,不加X锁,否则需要X锁;Table Filter过滤条件,无论是否满足,都需要加X锁
从图中可以看出,在Repeatable Read隔离级别下,由Index Key所确定的范围,被加上了GAP锁;Index Filter锁给定的条件 (userid = ‘hdc’)何时过滤,视MySQL的版本而定,在MySQL 5.6版本之前,不支持Index Condition Pushdown(ICP),因此Index Filter在MySQL Server层过滤,在5.6后支持了Index Condition Pushdown,则在index上过滤。若不支持ICP,不满足Index Filter的记录,也需要加上记录X锁,若支持ICP,则不满足Index Filter的记录,无需加记录X锁 (图中,用红色箭头标出的X锁,是否要加,视是否支持ICP而定);而Table Filter对应的过滤条件,则在聚簇索引中读取后,在MySQL Server层面过滤,因此聚簇索引上也需要X锁。最后,选取出了一条满足条件的记录[8,hdc,d,5,good],但是加锁的数量,要远远大于满足条件的记录数量。