RPC 框架能够帮助我们解决系统拆分后的通信问题,并且能让我们像调用本地一样去调用远程方法,隐藏底层网络通信的复杂性,让我们更专注于业务逻辑。java中的实现, § dubbo
前置知识
- RPC是一个远程调用,需要通过网络来传输数据,为了可靠性,一般会采用TCP来传输数据。
RPC 是一个远程调用,那肯定就需要通过网络来传输数据,并且 RPC 常用于业务系统之间的数据交互,需要保证其可靠性,所以 RPC 一般默认采用 TCP 来传输。我们常用的 HTTP 协议也是建立在 TCP 之上的 - 网络传输的数据必须是二进制数据,将调用方参数转换成二进制,为序列化。 object—> byte[]
网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是肯定没法直接在网络中传输的,需要提前把它转成可传输的二进制,并且要求转换算法是可逆的,这个过程我们一般叫做“序列化”。 - 协议,即数据格式的约定内容。因TPC会有黏包等问题,需要根据协议约定来编解码,解析二进制中的数据。
调用方持续地把请求参数序列化成二进制后,经过 TCP 传输给了服务提供方。服务提供方从 TCP 通道里面收到二进制数据,那如何知道一个请求的数据到哪里结束,是一个什么类型的请求呢?
在这里我们可以想想高速公路,它上面有很多出口,为了让司机清楚地知道从哪里出去,管理部门会在路上建立很多指示牌,并在指示牌上标明下一个出口是哪里、还有多远。那回到数据包识别这个场景,我们是不是也可以建立一些“指示牌”,并在上面标明数据包的类型和长度,这样就可以正确的解析数据了。确实可以,并且我们把数据格式的约定内容叫做“协议”。
大多数的协议会分成两部分,分别是数据头和消息体。- 数据头一般用于身份识别,包括协议标识、数据大小、请求类型、序列化类型等信息;
- 消息体主要是请求的业务参数信息和扩展属性等
- 反序列化,服务提供方将网络中的二进制数据还原成对象. byte[] —> object
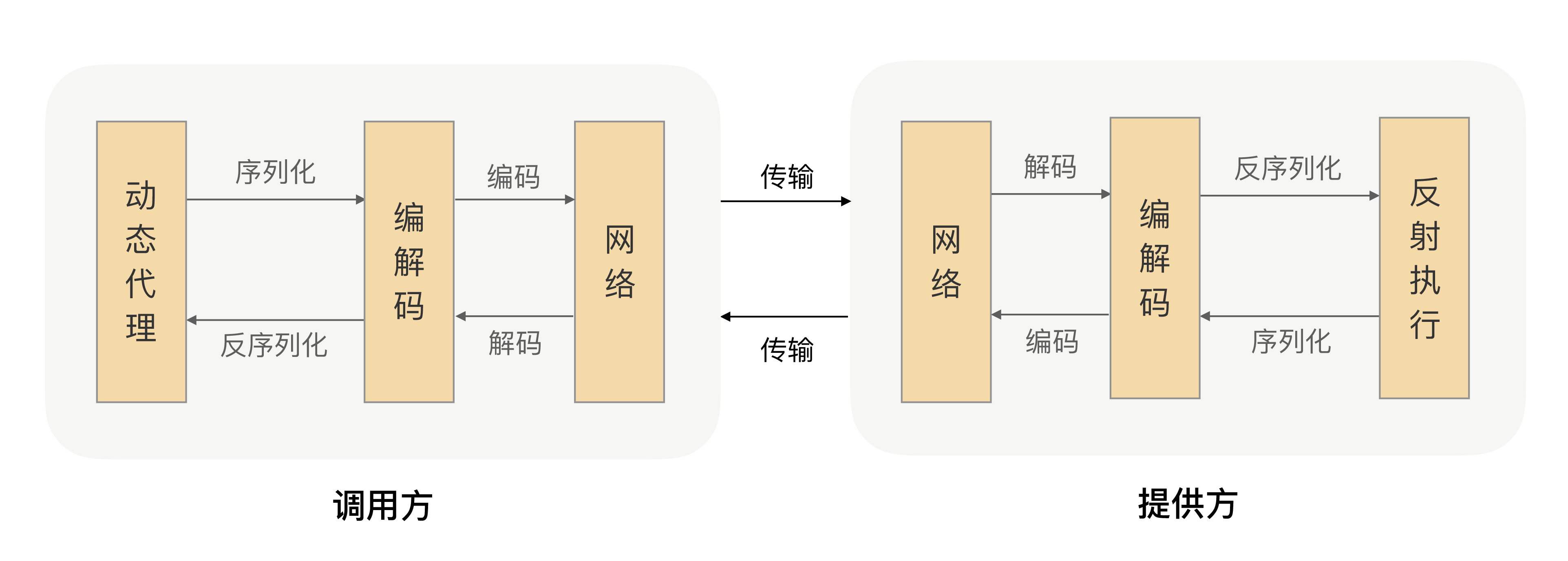
RPC框架调用过程
数据流转过程: 发送方(数据对象—> 序列化 —> 编码 —> 传输) —> 接收方: (解码 —> 反序列化 —> 数据对象)
- 调用方通过动态代理,像本地方法一样调用本地服务。
- 动态代理方法中。将调用出入参,序列化成byte( 网络传输必须是二进制数据)
- 在传输之前,根据”协议”进行编码.防止tcp黏包等问题
- 进行网络传输,发送二进制数据
- 提供方,接收到网络传输的二进制数据,进行解码。正确地从二进制数据中分割出不同的请求来。
- 提供方,根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象,反序列化
- 提供方,根据请求对象的出入参,进行反射调用执行方法。
- 响应数据根据 发送方: 序列化 —> 编码 —> 传输 —> 接收方: 解码 —> 反序列化进行获取数据对象
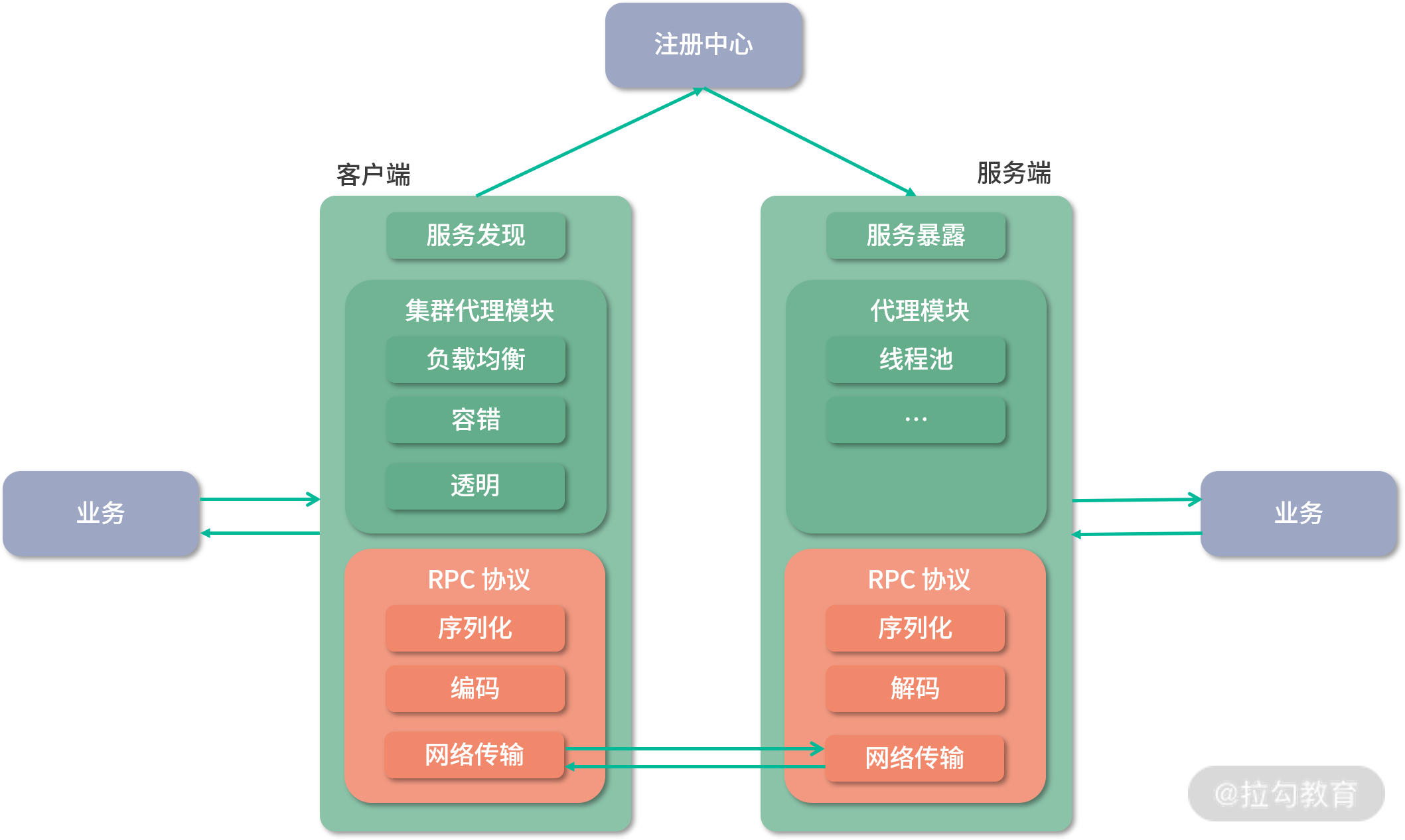
相对完整的RPC框架架构图
笔记
相对完整的、通用的 RPC 框架涉及很多方面的内容,例如注册发现、服务治理、负载均衡、集群容错、RPC 协议等
交互流程图:
- Client 首先会调用本地的代理,也就是图中的 Proxy。
- Client 端 Proxy 会按照协议(Protocol),将调用中传入的数据序列化成字节流。
- 之后 Client 会通过网络,将字节数据发送到 Server 端。
- Server 端接收到字节数据之后,会按照协议进行反序列化,得到相应的请求信息。
- Server 端 Proxy 会根据序列化后的请求信息,调用相应的业务逻辑。
- Server 端业务逻辑的返回值,也会按照上述逻辑返回给 Client 端。